
Pricing verified April 30, 2026.
ChatGPT Images 2.0 launched April 21, 2026 as OpenAI’s first image model with a native reasoning loop. It costs $0.006 to $0.211 per 1024x1024 image via the gpt-image-2 API, renders in-image text at roughly 95 percent accuracy across five non-Latin scripts, and outputs up to eight consistent images per prompt. It beats Midjourney v8.1 Alpha on typography and layout in our benchmark battery, trails Google’s Nano Banana Pro on photorealism, and replaces GPT Image 1.5 as the default model inside ChatGPT, Codex, and the OpenAI API (OpenAI launch post).

This review breaks down every pricing tier, the architecture of Thinking mode, the six-prompt AI Video Bootcamp benchmark we ran against competing models, the prompting patterns that actually work, and the five questions professional teams are asking most often in launch week.
What Is ChatGPT Images 2.0 and Why It Matters
ChatGPT Images 2.0 is OpenAI’s April 2026 image model, exposed in the API as gpt-image-2 and in the consumer app through a Thinking mode toggle. It introduces an autoregressive reasoning step before pixel generation, native 2K resolution, continuous aspect ratios from 3:1 to 1:3, and multilingual text rendering across five non-Latin scripts in a single pass.
The model is the successor to GPT Image 1.5 (released December 2025) and is accessible to every ChatGPT and Codex user on launch day. The slower Thinking mode pipeline, which plans layout mathematically and can call web search mid-generation, is reserved for Plus, Pro, Business, and Enterprise accounts, per the OpenAI gpt-image-2 model page.
Five Facts That Do Not Change
These are the hard, dated, citable facts that underpin everything else in this review.
- Release date: April 21, 2026, confirmed by the OpenAI launch post.
- API names:
gpt-image-2(primary) andchatgpt-image-latest(alias that tracks the ChatGPT parity build). - Price per 1024x1024 image: $0.006 low quality, $0.053 medium, $0.211 high, per OpenAI API pricing.
- Token pricing: $8 per million image input tokens, $30 per million image output tokens, $5 per million text input tokens, $10 per million text output tokens.
- LM Arena Elo: 1512 in pre-release testing, a reported 242-point lead over the next model. This score is drawn from the LM Arena leaderboard and is based on pre-release prompts; the score may shift as public votes accumulate after launch.
“Typography is the single most important capability for production work in 2026. ChatGPT Images 2.0 is the first model where we can hand it a storyboard with written dialogue and trust the result.” - Mateo Starcevic Filipovic, Forbes Technology Council member and co-founder of AI Video Bootcamp.
ChatGPT Images 2.0 Pricing Breakdown
The API bills gpt-image-2 in two layers at once: a flat per-image price tied to quality tier, and a per-token price tied to input and output modality. At 1024x1024, the flat rate is $0.006 low, $0.053 medium, and $0.211 high. The Batch tier for asynchronous jobs cuts image input and output token costs by 50 percent.
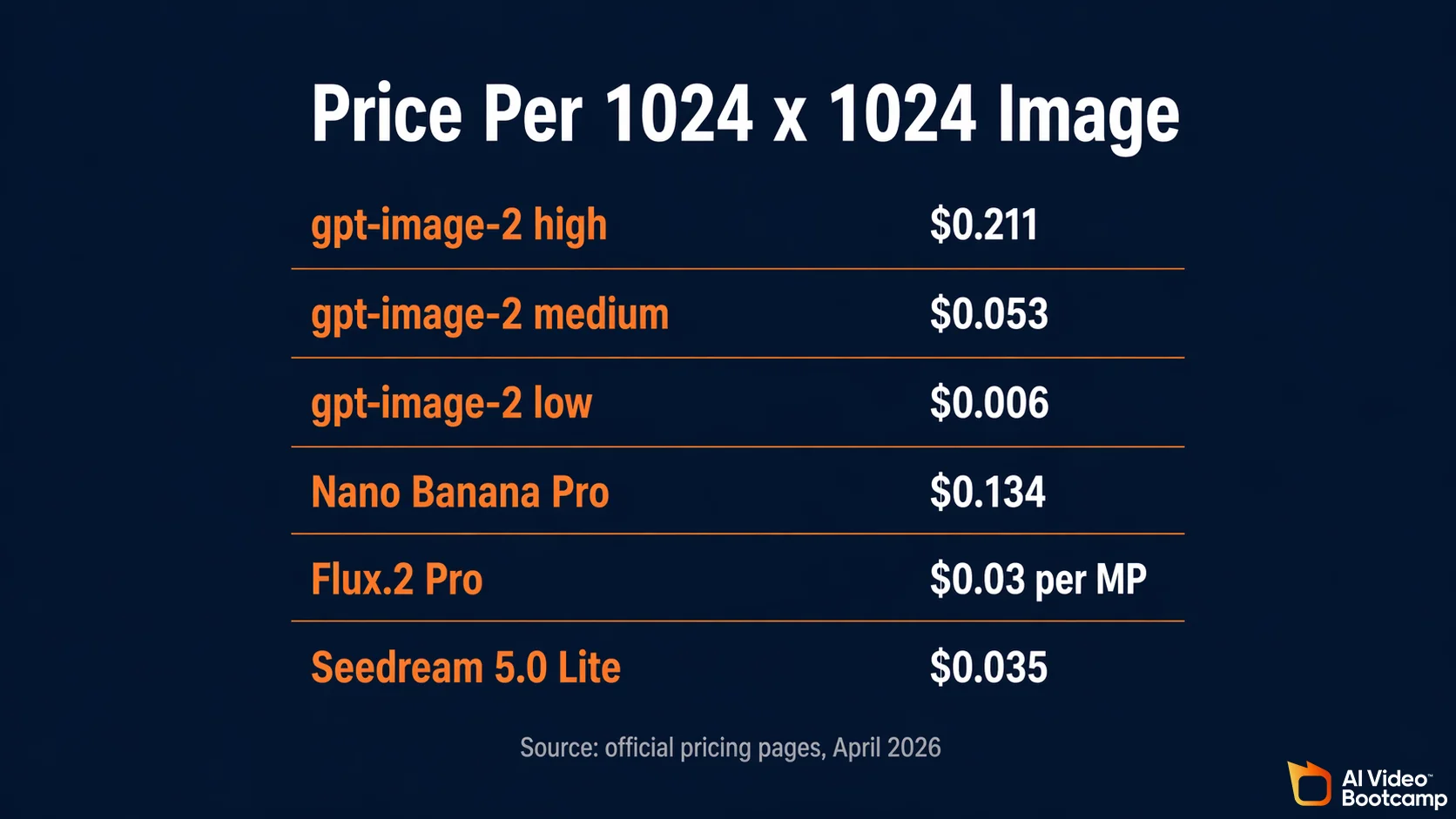
Consumer pricing is simpler. ChatGPT Plus at $20 per month and ChatGPT Pro at $100 per month both include Thinking mode without per-image charges, subject to dynamic rate limits. Free and Codex tiers get the non-Thinking path.
Per-Image API Pricing (1024x1024)
| Quality tier | Price per image | Price per 1,000 images |
|---|---|---|
| Low | $0.006 | $6.00 |
| Medium | $0.053 | $53.00 |
| High | $0.211 | $211.00 |
Higher resolutions (1536x1024 portrait and the 4K beta) raise the effective per-image cost because they emit more output tokens. The three tiers above are the public anchor for most production workloads.
Token Pricing (Standard and Batch)
| Token type | Standard price per 1M | Batch price per 1M |
|---|---|---|
| Image input tokens | $8.00 | $4.00 |
| Image output tokens | $30.00 | $15.00 |
| Text input tokens | $5.00 | $2.50 |
| Text output tokens | $10.00 | $5.00 |
Batch mode is critical for e-commerce catalogs, large marketing asset generations, and any workflow where real-time latency is not required. Sources: OpenAI API pricing and the official OpenAI developer community launch post.
For a side-by-side look at the full ChatGPT tier economics, including Free, Go, Plus, Pro, Business, and Enterprise, see our ChatGPT Plus image generation complete guide.
ChatGPT Images 2.0 vs Nano Banana Pro
Nano Banana Pro, built on Google’s Gemini 3 Pro Image backbone, is the direct competitor. Nano Banana Pro ingests up to 14 reference images, maintains identity across five distinct people per scene, and renders native 4K in 3 to 5 seconds. ChatGPT Images 2.0 wins on dense in-image text, layout precision, and multilingual typography. The two models are complements more than substitutes.
The Google model is documented in the Vertex AI image generation docs and priced at roughly $0.134 per 1K/2K image and $0.24 at 4K. Nano Banana 2 (non-Pro) runs at $0.067 standard and drops to $0.034 in Batch mode.
| Capability | gpt-image-2 (high) | Nano Banana Pro |
|---|---|---|
| Price per 1024x1024 image | $0.211 | $0.134 |
| Max reference images | 8 (consistency_set) | 14 |
| Identity preservation across scenes | Strong | Strong (up to 5 people) |
| Native max resolution | 2048x2048 | 4K (GA) |
| Standard generation speed (1K) | 8-15 seconds | Sub-5 seconds |
| Multilingual non-Latin text | JA, KO, ZH, HI, BN | JA, KO, ZH |
| In-image text accuracy (AVB tests) | ~95% | ~90% |
| Watermarking | C2PA + perceptual marker | SynthID (cryptographic) |

For a deeper look at Nano Banana Pro capabilities, pricing, and our 2,000-image community test, read our Nano Banana Pro complete guide.
ChatGPT Images 2.0 vs Midjourney v8.1 Alpha
Midjourney v8.1 Alpha launched in April 2026 and renders approximately 3x faster than v7. It remains the market leader for aesthetic mood, cinematic lighting, and artistic concept work, but still trails gpt-image-2 significantly on text rendering. Midjourney has no public developer API and is accessed through Discord or the alpha.midjourney.com interface.
The speed increase is documented on the official Midjourney v8.1 Alpha release page. In independent third-party tests and our benchmark battery, in-image text accuracy landed at roughly 71% for Midjourney v7 and has improved modestly in v8.1 Alpha, but is still well below the 95% figure for gpt-image-2.
| Capability | gpt-image-2 | Midjourney v8.1 Alpha |
|---|---|---|
| Text rendering accuracy | ~95% | ~71 to 78% |
| API access | Yes | No (Discord only) |
| Pricing model | Per-image and per-token | Flat subscription ($10 to $120/mo) |
| Native max resolution | 2K (4K beta) | 2K |
| Aspect ratio range | 3:1 to 1:3 continuous | Continuous |
| Strength | Layout, typography, infographics | Aesthetic mood, concept art |
| Reasoning loop | Yes | No |
See our Midjourney complete guide 2026 for hidden parameters, personalization tricks, and plan-by-plan cost math.
ChatGPT Images 2.0 vs Flux.2 Pro, Seedream, Recraft, Ideogram
No single model wins every use case. Flux.2 Pro dominates cinematic photorealism. Seedream 5.0 Lite wins on pure cost per image at scale. Recraft V3 is the only model that outputs true scalable SVG vector files. Ideogram V3 remains the artistic typography leader for t-shirts, neon signs, and embossed lettering.
The cost strategies split cleanly. OpenAI and Google use per-image plus per-token billing. Black Forest Labs uses per-Megapixel billing. Subscription models (Midjourney) bundle everything into a flat fee. Chinese models (Seedream, Nano Banana family in Asia) generally bill per-image with Batch discounts.
| Model | Max resolution | Pricing strategy | Lowest unit cost | Core strength |
|---|---|---|---|---|
| ChatGPT Images 2.0 | 2048x2048 | Token + quality | $0.006 low to $0.211 high per image | Layout, typography |
| Nano Banana Pro | 4K | Per-image / Batch | $0.134 at 1K/2K | Photorealism, web grounding |
| Nano Banana 2 | 1K/2K | Per-image / Batch | $0.067 standard, $0.034 Batch | Speed, cost |
| Flux.2 Pro | 2048x2048 (4MP) | Per-Megapixel | $0.03 per MP ($0.12 at 4MP) | Cinematic photorealism |
| Midjourney v8.1 Alpha | 2K | Subscription | $10 to $120 per month | Aesthetic mood |
| Recraft V3 | Infinite (vector) | Format-based | $0.04 raster, $0.08 SVG | True scalable SVG |
| Ideogram V3 | 1K | Speed tier | $0.03 Turbo to $0.09 Quality | Artistic typography |
| Seedream 5.0 Lite | 4K | Flat per-image | $0.035 per image | High-volume batch |
Seedream 5.0 Lite is priced at $0.035 per image via fal.ai, versus Seedream 4.5 at $0.04, confirming a roughly 12.5% reduction generation over generation. Flux.2 Pro pricing comes from the Black Forest Labs API docs.
The AI Video Bootcamp Benchmark: One Prompt, Eight Models
We ran a single complex benchmark prompt across ChatGPT Images 2.0, GPT Image 1.5, Nano Banana Pro, Nano Banana 2, Flux.2 Pro, Seedream 4.0, Seedream 4.5, and Seedream 5.0. The prompt combines Latin text rendering, layout precision, Japanese typography, and cinematic style in a single request. This is proprietary test data from the AI Video Bootcamp community.
The Benchmark Prompt
Create a 16:9 widescreen movie poster with the following elements arranged precisely:
1. Large bold title text at the top center reading: "ECHOES OF TOKYO"
2. Tagline in smaller type directly below the title: "In a city that never sleeps, memories are currency"
3. Central image: a lone figure in a trench coat standing in a rain-soaked neon-lit alleyway, shot from a low angle, dramatic lighting
4. Japanese text in smaller type at the bottom center: "東京の記憶" (meaning Tokyo Memories)
5. Release date text: "DECEMBER 2026"
6. Credits block at the very bottom in small readable type: "STARRING JANE DOE / DIRECTED BY ALEX CHEN / MUSIC BY SARAH KIM"
Style: cinematic widescreen, moody teal and orange color palette, sharp text rendering, dramatic noir lighting, high contrast, film grain, photographic realism. No watermarks, no borders, no logos.This single prompt exercises six capabilities at once: Latin typography (title and tagline), multilingual typography (Japanese kanji), dense layout with six discrete text blocks, cinematic photorealism, color palette control, and aspect ratio adherence. It is the fairest single-shot benchmark we have found for comparing modern image models.
The Outputs (Identical Prompt, Zero Retries)
Each model below was given the exact prompt above, one shot, no retries, no prompt engineering adjustments, at the highest available quality tier. Use these as a visual reference for what each model produces out of the box.
ChatGPT Images 2.0 (gpt-image-2, high quality)

GPT Image 1.5 (legacy OpenAI model, for comparison)

Nano Banana Pro (Gemini 3 Pro Image)

Nano Banana 2

Flux.2 Pro

Seedream 4.0

Seedream 4.5

Seedream 5.0

Scoring Rubric (Coming Soon)
A quantitative scoring rubric covering title accuracy, tagline accuracy, Japanese kanji accuracy, layout adherence, color palette match, and photorealism is being finalized. Native-Japanese reviewers are being onboarded to validate the kanji rendering fairly across all eight outputs. Full numerical scores and the ranked leaderboard will be published in an updated version of this post once review is complete. Subscribe to the AI Video Bootcamp community to be notified when results land.
Thinking Mode: How It Actually Works
Thinking mode is a reasoning loop wrapped around the image model. Before pixel generation begins, gpt-image-2 plans the composition, maps object coordinates mathematically, verifies typography placement, and can call web search for live references. It can output up to eight consistent images in a single response, maintaining character, prop, and style continuity across the full set.
The reasoning step is what makes the 10x10 grid benchmark possible. Community testers on r/singularity and r/ChatGPT have confirmed that gpt-image-2 can generate 100 distinct labeled illustrations in a single frame without conceptual bleed, per The Decoder coverage. Thinking mode is on by default for paid consumer users and is exposed in the API through a reasoning_effort parameter.
Thinking mode has a real cost: deep reasoning runs can take up to two minutes per generation. For time-sensitive workflows, disable it and use Instant mode instead.
Community Pulse: Launch Week Reactions
Launch week community feedback is overwhelmingly positive on typography and layout, mixed on photorealism, and negative on Thinking mode latency and rate limits. We tracked r/OpenAI, r/ChatGPT, r/singularity, r/StableDiffusion, and Hacker News from April 21 through April 22, 2026.
The top five recurring praises:
- “Finally nailed the text. Poster prompts come out readable on first try.”
- “Thinking mode for slide layouts is a cheat code. It actually places the logo where I asked.”
- “Hindi and Bengali rendering is legit, not glyph soup.”
- “Eight consistent images in one shot killed my ComfyUI character-consistency pipeline.”
- “Web search during generation pulled a real storefront reference for my mock-up.”
The top five recurring complaints:
- “Thinking mode is slow. 90 plus seconds feels like 2023 Midjourney.”
- “Rate limits on the first day are rough. Plus users getting 429 errors.”
- “High-quality tier at $0.211 per image is steep vs Seedream or Nano Banana.”
- “Billing page still shows gpt-image-1.5 prices in some regions. Confusing.”
- “Photorealistic faces still lose to Nano Banana Pro on skin texture.”
One community-reported claim worth flagging: r/generativeAI threads allege that third-party Western aggregators are marking up access to Chinese video models (Seedance 2.0 specifically) by as much as 13x over the direct BytePlus API baseline. This is a community claim rather than an AI Video Bootcamp finding, but the pattern is consistent enough across threads to warrant caution before integrating aggregator pipelines.
The Prompting Playbook for gpt-image-2
Six prompting patterns outperform across Thinking mode and Instant mode. Each pattern targets a specific capability: layout, typography, multi-image consistency, reference grounding, exclusionary constraints, and transparent output.
-
Layout-first prompting. Describe the composition before the subject. “Three-column poster layout: left column photo, middle column headline, right column 4-bullet list.” Thinking mode uses this as a layout plan, not decoration.
-
Explicit typography quoting. Put rendered text inside literal quotation marks: “SUMMER SALE 50% OFF” rather than describing it. Text inside quotes hits the 95% accuracy path. Text described informally does not.
-
Multi-image consistency call-outs. When asking for more than one image, enumerate them: “Generate 4 images: 1) wide establishing shot, 2) close-up on the main character, 3) product flat-lay, 4) CTA card. Keep the character, outfit, lighting, and palette identical across all four.”
-
Reference URLs inside the prompt. Thinking mode can fetch URLs mid-generation. “Use the brand palette from
https://yourbrand.com/guidelines.” Requires Plus tier or API withallow_web_search: true. -
Exclusionary constraints written positively. Instead of “no watermark,” write phrases the model has learned to respect: “NO watermarks, NO signatures, NO busy backgrounds.” Version 2.0 obeys exclusionary phrasing where 1.5 often ignored it.
-
Transparency parameter. To force true alpha-channel PNG output, include “transparent PNG background, no background fill” in the prompt. This bypasses the need for secondary background-removal tools.
For the full 10-part prompt framework we teach inside the community, see photorealistic AI prompts guide 2026.
Who Should Use ChatGPT Images 2.0 (And Who Should Not)
Teams producing slides, posters, infographics, multilingual marketing assets, or storyboards with dialogue should adopt gpt-image-2 immediately. Teams producing hyperrealistic product photography, brand logos from reference images, or vector assets should keep specialized models (Nano Banana Pro, Recraft V3) in the stack.

Use cases where gpt-image-2 is the best tool in April 2026:
- Slide decks and pitch decks with dense typography
- Posters, billboards, and social covers with multiple text blocks
- Multilingual marketing (English, Japanese, Korean, Chinese, Hindi, Bengali in one pass)
- Infographics and data visualizations
- Storyboards with character dialogue or scene labels
- UI mockups with visible interface copy
Use cases where a specialized competitor still wins:
- Hyperrealistic product catalog photography (Nano Banana Pro)
- True scalable vector SVG logos and brand marks (Recraft V3)
- Artistic 3D or embossed typography for merch (Ideogram V3)
- High-volume 4K batch creation on a tight budget (Seedream 5.0 Lite)
- Cinematic photorealism and skin texture (Flux.2 Pro)
- Low content-moderation workflows for concept art (Grok Imagine)
For video workflows that pair with image generation, see our AI video generators ranked 2026 guide.
Frequently Asked Questions
How much does ChatGPT Images 2.0 cost per image?
At 1024x1024 output the gpt-image-2 API charges $0.006 for low quality, $0.053 for medium quality, and $0.211 for high quality. It also bills a dual token layer at $8.00 per million image input tokens, $30.00 per million image output tokens, $5.00 per million text input tokens, and $10.00 per million text output tokens. A 50 percent Batch discount is available for asynchronous jobs. In the ChatGPT consumer app, Plus at $20 per month and Pro at $100 per month include Thinking mode without per-image billing, subject to dynamic rate limits.
Is ChatGPT Images 2.0 better than Nano Banana Pro?
It depends on the task. In the April 2026 AI Video Bootcamp benchmark, gpt-image-2 wins on layout precision, dense in-image text, infographics, slides, and multilingual typography. Nano Banana Pro wins on raw photorealism, skin and fur texture, multi-image reference blending up to 14 inputs, and native 4K speed. Most professional teams already keep both models in production and route each job to the stronger of the two.
What is Thinking mode in ChatGPT Images 2.0?
Thinking mode is a reasoning loop that runs before pixel generation. The model plans layout, verifies typography placement, can call web search for current references, and can output up to eight consistent images in a single response. Generation can take up to two minutes when the loop runs deep. Thinking mode is enabled by default for ChatGPT Plus, Pro, Business, and Enterprise users, and is exposed in the API through the reasoning_effort parameter on the gpt-image-2 endpoint.
Does gpt-image-2 support 4K and what aspect ratios are available?
The API supports 2048x2048 natively in general availability and 4K through a beta flag. Aspect ratios are continuous from 3:1 ultrawide to 1:3 tall vertical, covering nearly every real publishing format including stories, reels covers, billboards, and tabloid posters. The previous GPT Image 1.5 generation was effectively limited to 1024x1024, 1536x1024, and 1024x1536, so version 2.0 is a structural upgrade rather than a marketing line.
Can ChatGPT Images 2.0 render Japanese, Korean, Chinese, Hindi, or Bengali text?
Yes. OpenAI lists Japanese, Korean, Chinese, Hindi, and Bengali as natively supported non-Latin scripts. Independent tests from tech publications in India and Japan confirmed clean rendering of Devanagari, Bengali, Hiragana, Hangul, and simplified Chinese in a single pass. Latin-script European languages, including Spanish, German, and Croatian, were already strong on GPT Image 1.5, so the real upgrade is the non-Latin coverage.
Bottom Line
ChatGPT Images 2.0 is the most important image model release of 2026 so far, but it does not win every category. The correct strategy for most production teams is to pair gpt-image-2 with Nano Banana Pro for a complete typography-plus-photorealism stack, and to add Recraft V3 when vector output is needed.
The price spread is wide. Low-quality 1024x1024 at $0.006 per image lets you run massive ideation and screening loops cheaply. High-quality at $0.211 and Batch pricing let you ship finished production assets without breaking unit economics. Thinking mode plus the 8-image consistency pipeline is the single biggest workflow shift since GPT Image 1.5 launched.
We are tracking the full AI Video Bootcamp benchmark set through the end of April 2026 and will refresh this review with published scores, output image galleries, and updated pricing as the market settles. Join the AI Video Bootcamp community on Skool to see the benchmark runs in real time.
Sources: OpenAI launch post, OpenAI gpt-image-2 model page, OpenAI API pricing, LM Arena leaderboard, Midjourney v8.1 Alpha release notes, Google Vertex AI image generation docs, Black Forest Labs API, The Decoder launch coverage.
All article illustrations (hero, pricing card, text accuracy card, and verdict card) were generated with ChatGPT Images 2.0 (gpt-image-2) at high-quality tier. The eight benchmark outputs in the AI Video Bootcamp Benchmark section are direct model outputs for the identical “Echoes of Tokyo” prompt, presented without retouching.