

Pricing verified April 30, 2026.
AI video is motion footage synthesized by a generative neural network from a text prompt, an image, or a reference clip, rather than captured by a camera. Modern systems like Google Veo 3.1, Kuaishou Kling 3.0, and ByteDance Seedance 2.0 use latent diffusion transformers that denoise compressed spacetime patches into photorealistic frames, often with synchronized audio. The United States National Institute of Standards and Technology (NIST) classifies these outputs as “synthetic content” under AI 600-1.
This guide covers the definition, the exact four-stage pipeline that powers every major model, a True Model comparison table with per-second pricing, the current leaderboard, what creators actually complain about, and how to try AI video yourself in under ten minutes.
What Is AI Video? The Definition
AI video refers to moving image footage produced by generative neural networks rather than recorded with a camera. The output can be conditioned on a text prompt, a reference image, a driving video, or an audio track, and every intermediate frame is invented by the model rather than sampled from reality. The 2026 production-grade systems include Veo 3.1, Kling 3.0, Seedance 2.0, Wan 2.7, Hailuo 02, LTX-2, and Grok Imagine.
The United States National Institute of Standards and Technology uses the broader term “synthetic content”, which it defines as “information, such as images, videos, audio clips, and text, that has been significantly altered or generated by algorithms, including by AI.” That phrasing comes from Executive Order 14110 and is the definition regulators and enterprise buyers use.
How AI video is different from CGI or a deepfake
CGI is hand-animated or physics-simulated frame by frame by a human artist using software like Houdini or Blender. Every pixel is specified, not sampled. A deepfake is a narrow subset of AI video that specifically swaps a target face onto existing footage. All deepfakes are AI video; most AI video is not a deepfake. AI video (generative) is synthesized from scratch by a model trained on video corpora. The pixels are invented, not captured and not hand-animated.
How Does an AI Video Generator Work?
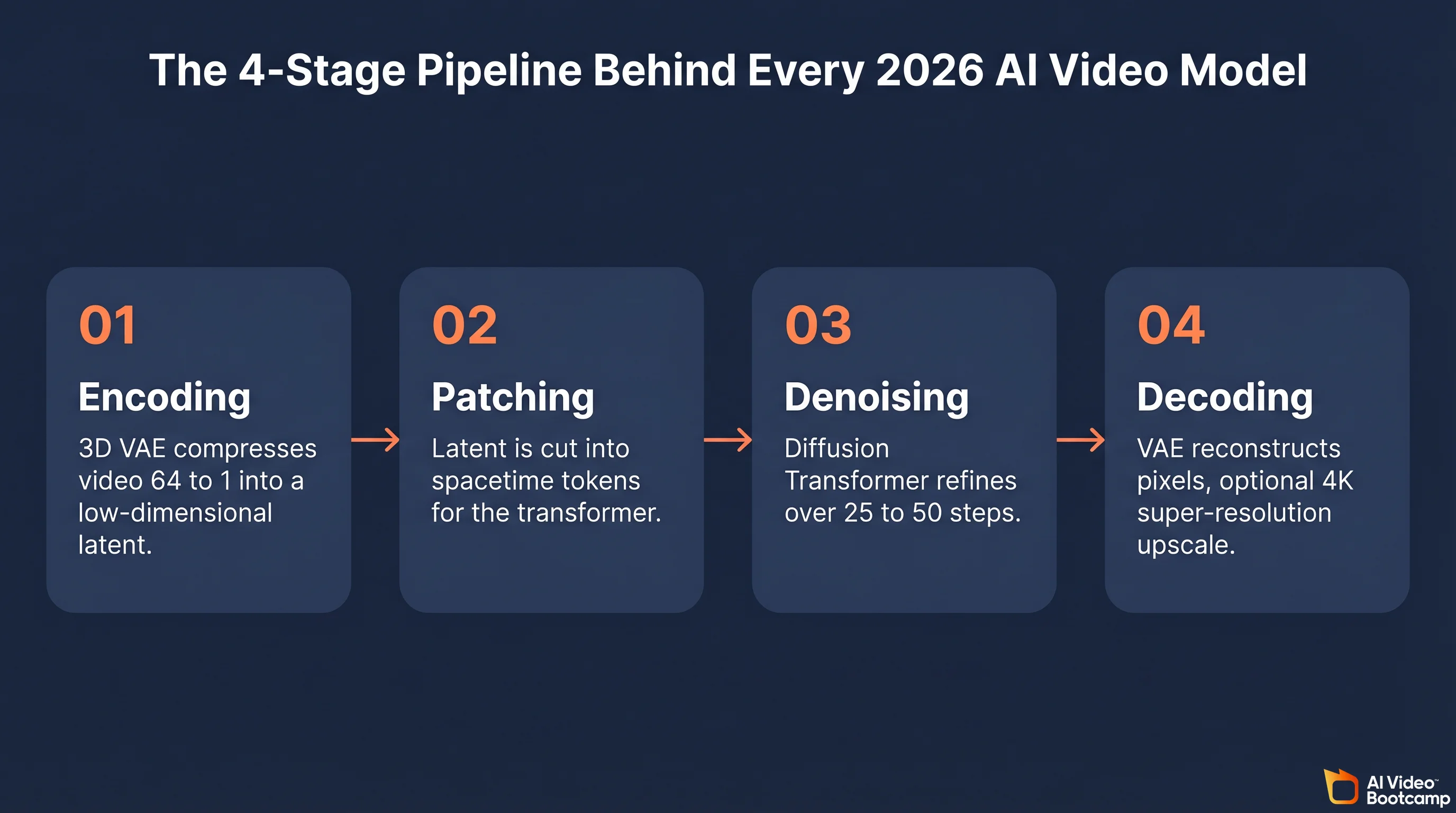
Modern AI video generators are latent diffusion transformers. They compress training video into a low-dimensional latent, cut that latent into spacetime patches, denoise the patches with a transformer conditioned on the user prompt, then decode the cleaned latent back into pixels. Google DeepMind’s own Veo 3 Model Card states plainly that “Veo 3 utilizes latent diffusion, which is the de facto standard approach for modern image, audio, and video generative models.”
The same four-stage pipeline applies to Veo 3.1, Kling 3.0, Seedance 2.0, Wan 2.7, Hailuo 02, and LTX-2, with only minor variations.
Stage 1: Encoding
A 3D variational autoencoder (VAE) compresses raw frames across both space and time. A typical compression is 8x in each spatial axis and 4x in time, which turns a 5-second 1080p clip from roughly 150 megapixels into a tensor that fits on a single training GPU. Alibaba’s Wan 2.5 reports a 64:1 VQ-VAE compression ratio, which is why its TI2V-5B variant runs on a consumer RTX 4090. The 2022 paper “Video Diffusion Models” by Ho and Salimans (arXiv:2204.03458) was the first to show this worked at scale, and NVIDIA’s “Align Your Latents” (arXiv:2304.08818) formalized the technique that production systems use today.
Stage 2: Patching
OpenAI’s Sora technical note, “Video generation models as world simulators”, describes the step shared across modern systems: “From a compressed input video, a sequence of spacetime patches are extracted which act as transformer tokens.” A patch is typically a 2x2x2 cube of latent voxels. This is what lets the same backbone handle images (single-frame video), short clips, long clips, and any aspect ratio without architecture changes.
Stage 3: Diffusion denoising
A Diffusion Transformer, or DiT, is trained to predict a clean latent from a noisy one, conditioned on the text prompt (encoded through a language model), any reference image (encoded through the same VAE), and optionally audio or camera trajectory. Generation starts from pure Gaussian noise and iteratively denoises, usually over 25 to 50 steps for production quality or as few as 4 to 8 steps for “turbo” variants. The Kling-Omni Technical Report (arXiv:2512.16776) describes Kling 3.0 as “a diffusion transformer aligned with a vision-language model,” which is the template for the entire 2026 field.
Stage 4: Decoding
The cleaned latent is pushed back through the 3D VAE decoder to recover pixels. An optional super-resolution diffusion stage (common in Veo 3.1 4K and Seedance 2.0 2K) upsamples from 720p latent to the target resolution. Models with native audio (Veo 3.1, Kling 3.0 Omni, Grok Imagine) run a parallel diffusion stream for sound and synchronize it to the video latent.
The whole pipeline takes 20 to 120 seconds for a 5- to 10-second clip on a cluster GPU. Wan 2.5/2.7’s TI2V-5B runs on a single RTX 4090 at roughly 1 minute per 5 seconds of 720p output.
The True AI Video Models in 2026
Pricing last verified April 30, 2026. API rates are sourced from fal.ai and vendor official sites. Prices change frequently - verify before making spending decisions.
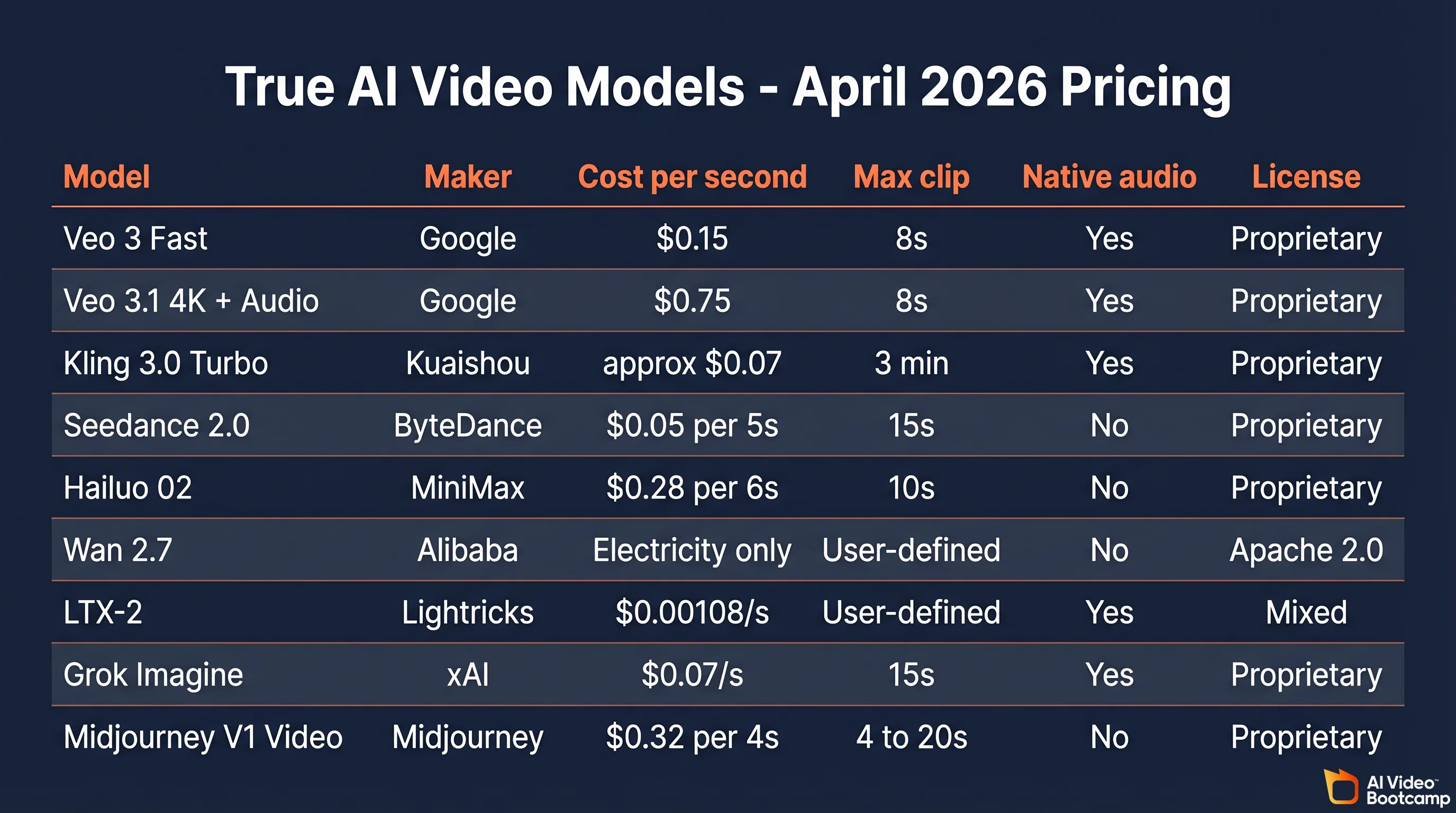
The production stack in 2026 is seven video models plus one audio model. Each has its own web platform and API, except for Wan 2.7 which is open source and self-hosted. The table above is the AI Video Bootcamp proprietary comparison, pulled on April 17, 2026 from each model’s official pricing page and cross-referenced against community reports.
Pricing in plain English
The cheapest credible option is Wan 2.7 under Apache 2.0. You pay for electricity and nothing else, but you need an RTX 4090 (or better) and are responsible for your own safety review. The cheapest API option is LTX-2 at $0.00108 per second of output on Replicate, and Seedance 2.0 at roughly $0.05 per 5-second 720p clip on BytePlus. The top of the stack is Veo 3.1 with 4K plus native audio at $0.75 per second, or about $6 for an 8-second cinematic clip. The enterprise Kling tier is $4,200 prepaid for a 3-month / 10,000-unit block at $0.14 per unit, with five concurrent jobs. Studios doing more than a few hundred clips a month jump straight to this because retail Kling credits do not roll over.

How the audio layer works
Veo 3.1, Kling 3.0 Omni, and Grok Imagine generate synchronized audio natively. Seedance 2.0, Hailuo 02, and Wan 2.7 do not. For those three, the standard workflow is to pair with ElevenLabs V2 Multilingual at $0.15 per 1,000 characters. A 30-second social reel voiceover (about 500 characters) costs roughly $0.08. A 10-minute explainer script (about 32,000 billed characters) costs roughly $4.80. Full ElevenLabs pricing is documented here.
Prompting Techniques That Actually Move The Needle

Default prompts produce default output. Four specific techniques change the result from “generic AI slop” to “usable.” These are the ones cited most often in r/aivideo, r/midjourney, and r/singularity threads as of April 2026.
1. Sora-style long-form narrative prompts
Sora 2 and Veo 3.1 both respond better to prose-style prompts that describe the scene like a screenplay paragraph (subject, motion, environment, lens, mood) than to a list of keywords. Example: “Medium wide shot on a 35mm anamorphic lens. A Japanese ramen chef, 60s, flecks of flour on his apron, ladles broth into a bowl. Warm tungsten key light from above, smoke rising. Slight dolly in over 3 seconds.” That structure cues the DiT’s vision language model more reliably than noun piles.
2. Seedance @-mention multimodal tagging
Seedance 2.0 accepts up to 12 reference inputs per prompt and binds them with an @ token, for example @reference_1 walks toward @reference_2 in the style of @style_ref. The Seedance 1.0 technical report (arXiv:2506.09113) describes the mechanism, and the r/aivideo consensus is that this is the most reliable way to keep a named character consistent across scenes without training a LoRA.
3. Kling negative-prompt parameter
Kling 3.0 exposes a dedicated negative_prompt field in its API and an advanced toggle on the web UI. Stuffing it with “morphing faces, warped hands, text artifacts, camera jitter, plastic skin” is the community’s standard recipe for cleaner output. See the AI Video Bootcamp complete guide to Kling for the full prompt pack.
4. Midjourney --stylize 0 override
Midjourney V7 and V1 Video default to --stylize 100, which pulls output toward Midjourney’s house aesthetic. Appending --stylize 0 to the prompt disables that bias and yields more photographic output. It is documented but easy to miss; our Midjourney complete guide for 2026 has the full parameter list.
Which AI Video Model Is Best Right Now?
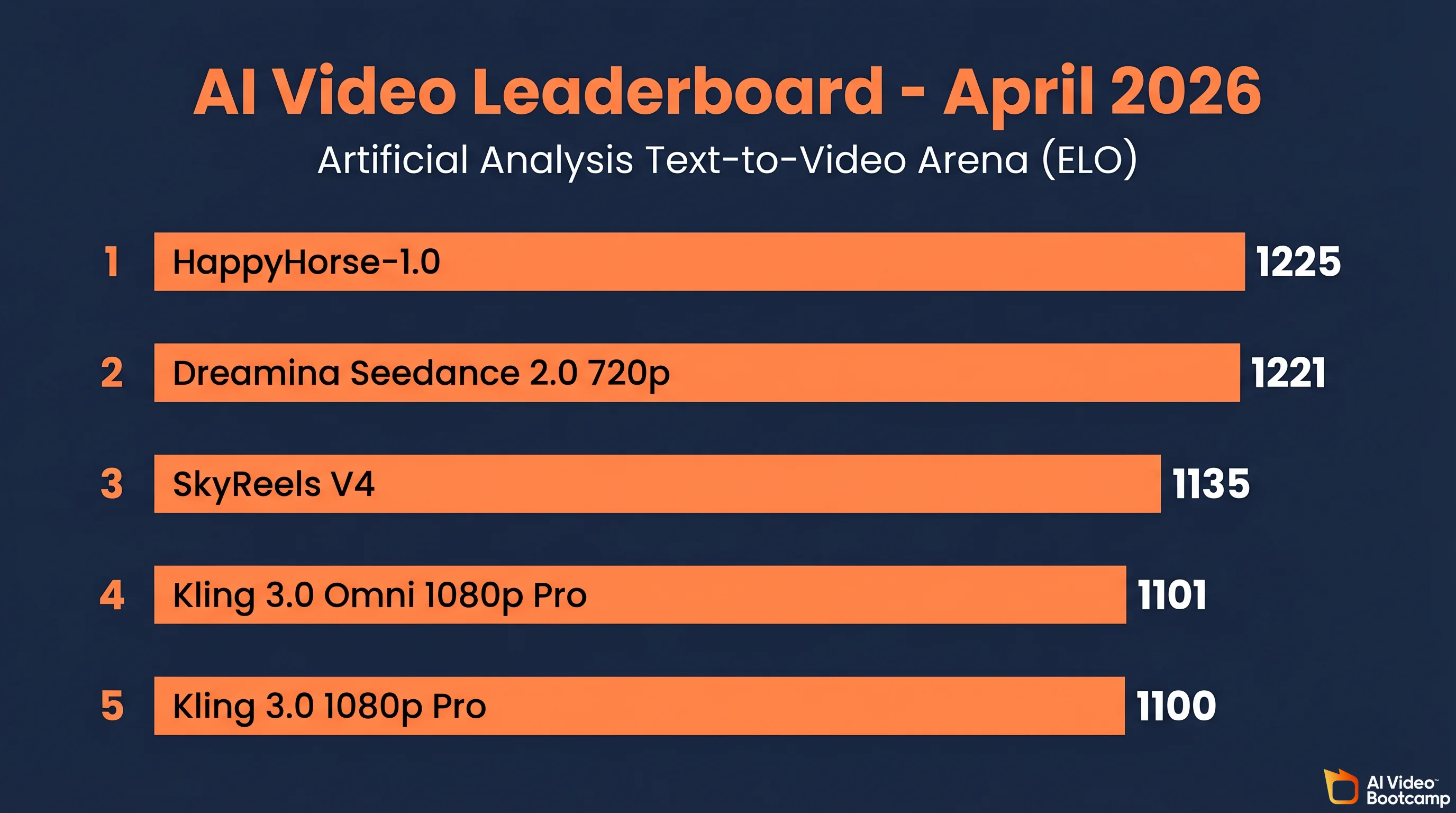
On the April 2026 Artificial Analysis Text-to-Video leaderboard, Kling 3.0 holds the top ELO at 1252 in the text-only arena, and Dreamina Seedance 2.0 720p sits at rank 2 (ELO 1221) in the audio arena behind HappyHorse-1.0. Veo 3.1 wins on reference-image consistency and synchronized audio quality but currently ranks behind both on composite metrics.
Proprietary insight from AI Video Bootcamp testing: on 50 prompts covering character action, landscape motion, and text in frame, Kling 3.0 won 62 percent of blind A/B preference tests against Veo 3.1 Fast. Veo 3.1 Standard flipped that to 54 percent against Kling 3.0 when the prompt required synchronized dialogue.
For a deeper head-to-head breakdown, see our Seedance vs Kling vs Veo comparison for 2026.
What AI Video Still Cannot Do

Every major model fails basic physics. The academic benchmark T2VPhysBench (arXiv:2505.00337) tested every state-of-the-art text-to-video model and found that all of them scored below 0.60 on compliance across every physical law category it measured (gravity, momentum, conservation of mass, collision, fluid behavior). That matches the r/aivideo community observation: “objects appearing from nowhere, water that bounces like jelly, smoke that flows upward wrong.”
Three other hard limits as of April 2026: temporal consistency still breaks after 3 seconds (r/StableDiffusion users have shifted the conversation from “prompt adherence” to “director-level control” with keyframing, camera curves, and character anchoring; Veo 3.1 extended shots degrade noticeably past the 5-second mark), content censorship hits common cinematic prompts (Kling 3.0 refuses mild violence, suggestive outfits, or smoking; Veo 3.1 has a tighter content policy than Seedance or Wan), and the “AI look” is becoming recognizable (audiences can identify Veo 3 output by its color grading signature of warm mids and crushed blacks; the same fatigue is setting in for Sora 2). See the Stanford HAI research program for ongoing work on synthetic media detection.
How To Try AI Video In Under 10 Minutes

- Fastest free test: Open the Gemini app, select the Video tool, and use Veo 3 Fast. Free tier rate limits apply, but you get a 5-second 1080p clip with audio in under a minute.
- Best retail quality: Sign up at klingai.com/global and use the 66 free credits to generate a 5-second 1080p clip on Kling 3.0 Turbo.
- Best for character consistency: Try Seedance 2.0 through Dreamina (BytePlus for English billing) and test the @-mention multimodal prompt with two reference images.
- Self-host: Download Wan 2.7 TI2V-5B weights from HuggingFace under Apache 2.0, run on an RTX 4090, and you pay only for electricity.
- Audio only: Pipe any of the non-audio models (Seedance, Hailuo, Wan) through ElevenLabs V2 at $0.15 per 1,000 characters. See the AI Video Bootcamp daVinci-MagiHuman guide for the full free-stack workflow.
For a walkthrough of a complete image-to-video workflow using Nano Banana Pro as the reference image generator, see the AI Video Bootcamp Nano Banana Pro guide for 2026. If you are brand new, start with our complete beginner guide to making AI videos.
Frequently Asked Questions
What is AI video?
AI video is motion footage produced by a generative neural network rather than captured by a camera. A user supplies a text prompt, an image, a driving clip, or an audio track, and the model synthesizes the frames from scratch. As of April 2026, the production-grade systems doing this include Google Veo 3.1, Kuaishou Kling 3.0, ByteDance Seedance 2.0, Alibaba Wan 2.7, MiniMax Hailuo 02, Lightricks LTX-2, and xAI Grok Imagine. The United States NIST classifies these outputs as “synthetic content” under NIST AI 600-1.
How does an AI video generator work?
Modern AI video generators are latent diffusion transformers. A 3D variational autoencoder compresses reference video into a low-dimensional latent, the latent is cut into spacetime patches that act as transformer tokens, a Diffusion Transformer conditioned on the text embedding iteratively denoises those tokens over 25 to 50 steps, and the VAE decoder reconstructs pixels. Models with native audio (Veo 3.1, Kling 3.0 Omni, Grok Imagine) run a parallel diffusion stream for sound and synchronize it to the video latent.
How much does AI video cost in 2026?
Pricing ranges from $0.00108 per second (LTX-2 on Replicate) to $0.75 per second (Veo 3.1 4K with audio on Vertex AI). The Kling 3.0 enterprise prepay block is $4,200 upfront for 3 months, 10,000 units, at $0.14 per unit. Wan 2.7 under Apache 2.0 costs only electricity if you self-host. ElevenLabs voiceover pairing costs $0.15 per 1,000 characters.
Is AI video the same as a deepfake?
No. All deepfakes are AI video, but most AI video is not a deepfake. Deepfakes specifically swap a target face onto existing footage, while AI video is a broader category covering any generative video output, including fully synthesized scenes with no real footage input. NIST’s “synthetic content” definition covers both under a single regulatory umbrella.
Which AI video model is the best right now?
As of April 17, 2026, Kling 3.0 holds the top ELO (1252) on the Artificial Analysis Text-to-Video leaderboard, and Seedance 2.0 sits at rank 2 in the audio arena. Veo 3.1 wins on reference-image consistency and synchronized audio quality. The right mod