

Pricing verified April 30, 2026.
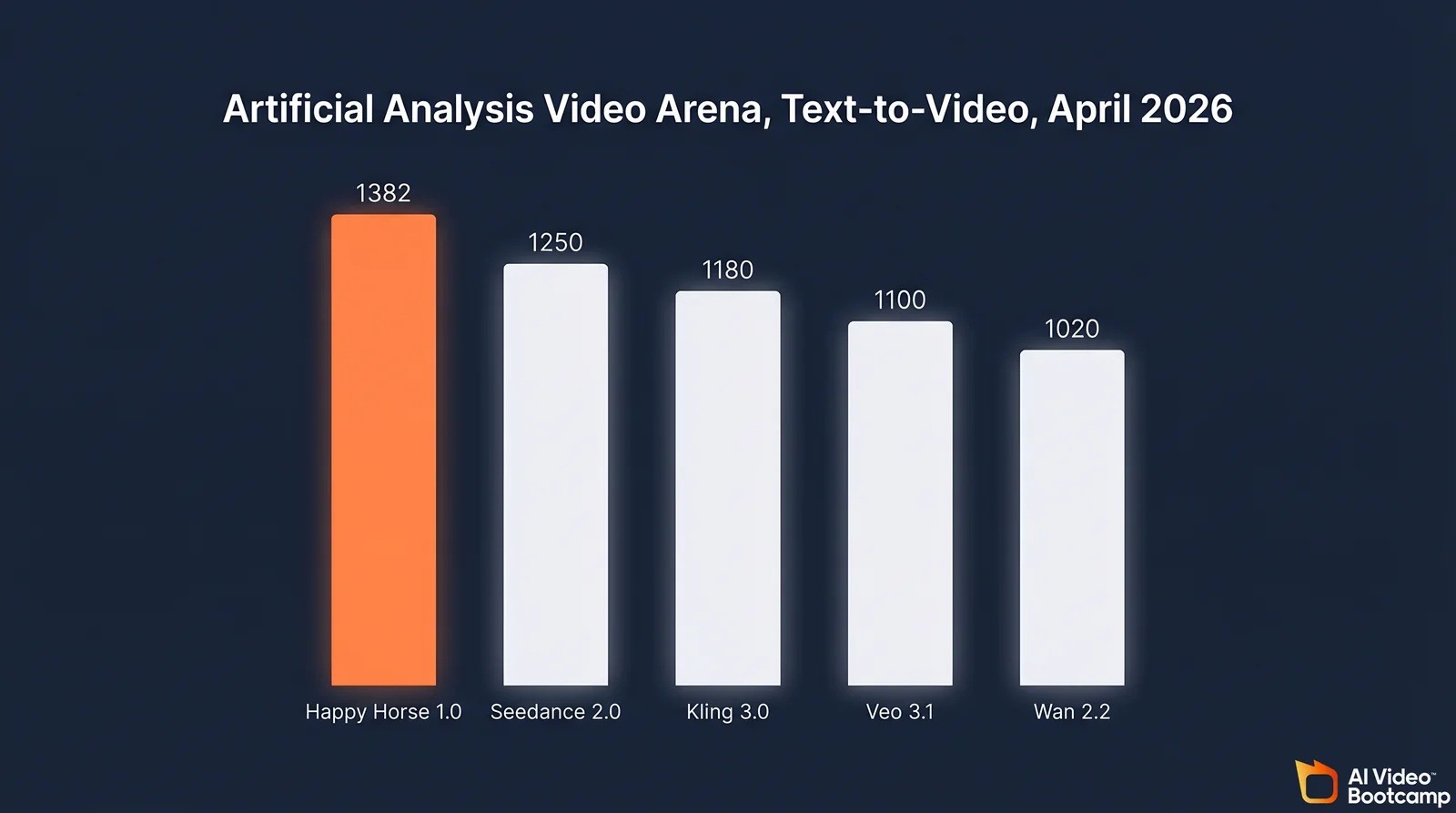
Happy Horse 1.0 is Alibaba’s 15-billion-parameter AI video model that took the #1 spot on the Artificial Analysis Video Arena on April 7, 2026 with a Text-to-Video Elo of 1,382 and an Image-to-Video Elo of 1,416. Built by the Taotian Future Life Lab under former Kling AI tech lead Zhang Di, it renders native 1080p video with synchronized audio in roughly 38 seconds on a single NVIDIA H100, using an 8-step DMD-2 distillation pipeline.
Key Data Points at a Glance
A few hard numbers to anchor this guide:
- 15-billion parameters in a single-stream, 40-layer Transformer (4 modality-specific layers at each end, 32 shared middle layers).
- Elo 1,382 Text-to-Video and Elo 1,416 Image-to-Video on the Artificial Analysis Video Arena as of April 8, 2026.
- 8 denoising steps using Distribution Matching Distillation v2 (DMD-2), versus 25 to 50 steps in legacy diffusion pipelines.
- ~38 seconds per 1080p clip on a single NVIDIA H100 GPU.
- April 7, 2026 anonymous debut; April 10, 2026 Alibaba attribution, triggering a 2.12% pop in Alibaba’s Hong Kong-listed shares that day.
What Is Happy Horse 1.0?
Happy Horse 1.0 is the codename for a generative AI video model developed inside Alibaba’s Taotian Group Future Life Laboratory, part of the ATH AI Innovation Unit. It generates both text-to-video and image-to-video output at native 1080p, with joint audio generation and phoneme-level lip-sync in seven languages. The model is not yet publicly available via API; enterprise access is scheduled for late April 2026.
The April 2026 Anonymous Debut
On April 7, 2026, an unbranded model called “Happy Horse 1.0” appeared on the Artificial Analysis Video Arena, a blind pairwise benchmark where human voters choose between two unlabeled clips. Within 72 hours it reached #1 globally in both Text-to-Video and Image-to-Video categories, ahead of ByteDance’s Seedance 2.0 and Google’s Veo 3.1. On April 10, Alibaba publicly took ownership of the project.

The stealth rollout was deliberate. Anonymous submissions force evaluators to judge a model on its output alone, stripping away the brand gravity that benefits releases from Google, ByteDance, or Kuaishou. It also gave Alibaba a near-perfect proof point for a market reveal.
The Team Behind It
The project is led by Zhang Di, a former Vice President at Kuaishou and the primary technical lead on the original Kling AI video model before he joined Alibaba in late 2025. His background gives the release unusual technical credibility: the architect behind one of China’s leading video models has now built a system that outranks it in blind tests.
Architecture: The Single-Stream Transformer Explained
Happy Horse 1.0 uses a unified single-stream Transformer instead of the cascaded, dual-branch pipelines common in 2025. All four modalities (text, image, video, audio) are concatenated into one token sequence and flow through 40 shared attention layers. There is no separate cross-attention module forcing alignment between branches, which is why audio and video stay causally synchronized in the final output.
How the 40-Layer Sandwich Works
The 15B-parameter Transformer is structured as a sandwich. The first four layers and the final four layers act as modality-specific encoders and decoders, converting text, images, video, and audio tokens into a shared dimensional space and back again. The middle 32 layers share parameters across every modality and do the heavy semantic work: learning how an object looks, how its geometry changes over time, and what sounds it produces when it moves or collides.
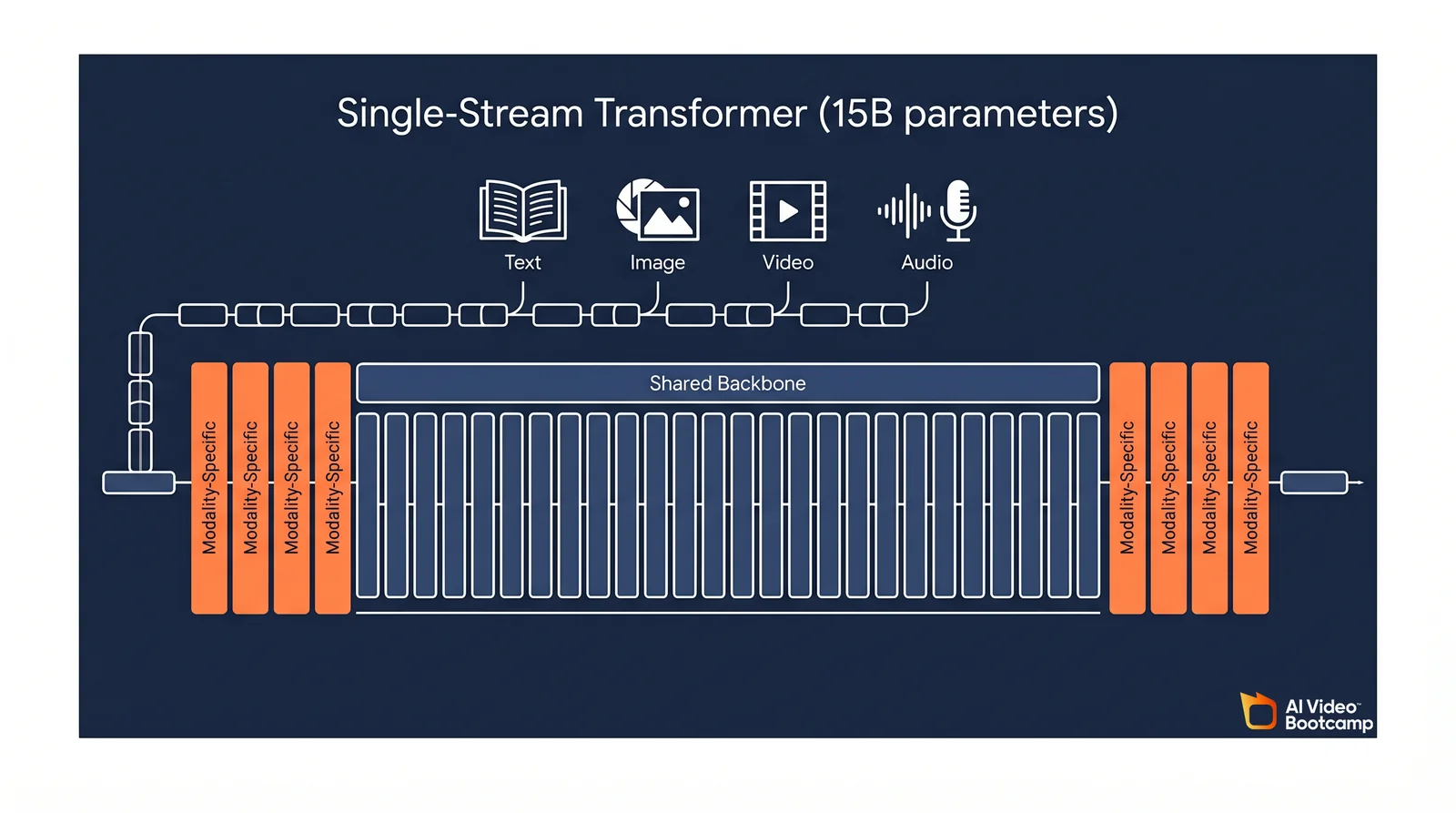
Because every modality passes through the same central stack, the model learns audio-visual causality as a native mathematical property rather than a post-hoc alignment step. When a prompt asks for “a heavy boot stepping onto a frozen lake,” the visual fracturing of the ice and the snap of the sound effect are generated together in the same forward pass. This is the single biggest architectural departure from legacy systems like the earlier Wan family or the branch-and-align approach used in most 2024-era models.
What Is Not Yet Verified
Several specific architectural details have circulated widely but lack a published technical paper to back them. These include per-attention-head learned sigmoid scalar gates, timestep-free denoising (inferring diffusion state from input noise levels), and a proprietary “MagiCompiler” graph-fusion tool claimed to add a 1.2x end-to-end speedup. These are reported across Alibaba-adjacent coverage but have not been confirmed through an arXiv preprint or a GitHub release. Treat them as reported until the technical report drops.
Inference Efficiency: 8-Step DMD-2 Pipeline
Happy Horse 1.0 uses Distribution Matching Distillation v2 (DMD-2) to compress what is typically a 25 to 50 step denoising trajectory down to just 8 steps. It also eliminates Classifier-Free Guidance, which in legacy models doubles compute by requiring a conditional and unconditional pass at every step. The result is 1080p generation in about 38 seconds on a single H100 GPU.
Why This Changes the Economics
Distribution Matching Distillation v2 is a published 2024 distillation method (see the arXiv preprint “Improved Distribution Matching Distillation for Fast Image Synthesis” by Yin et al., 2024) that trains a lightweight student model to reproduce the distribution of a teacher model in a fraction of the sampling steps. By applying DMD-2 and cutting CFG, Happy Horse 1.0 halves the raw compute load per clip compared to the 50-step pipelines that still dominate enterprise deployments.
For a high-volume social media team or an agency rendering thousands of clips a week, that efficiency changes the unit economics. Faster inference means shorter queues, more iterations per day, and lower per-clip infrastructure cost for whoever ends up hosting the public endpoint.
Happy Horse 1.0 vs. the Top 2026 AI Video Models
Against the 2026 True Models, Happy Horse 1.0 leads on Elo ranking and inference speed but lags on resolution (1080p native vs. Kling’s 1080p+ or Veo’s 1080p at higher bitrate) and duration (5 to 10 seconds vs. Seedance 2.0’s 15 second ceiling). Its unique edge is native joint audio-visual generation in a single forward pass, which no other leading model matches end-to-end.
Technical Comparison Table
| Feature | Happy Horse 1.0 | Seedance 2.0 Pro | Kling 3.0 Pro | Veo 3.1 | Wan 2.2 |
|---|---|---|---|---|---|
| Developer | Alibaba (ATH) | ByteDance | Kuaishou | Google DeepMind | Alibaba |
| Core architecture | Unified single-stream (15B) | Dual-branch diffusion | Omni-diffusion | Proprietary DeepMind stack | Latent diffusion |
| Max native resolution | 1080p | 1080p | 1080p | 1080p | 1080p |
| Max clip duration | 5 to 15 seconds | 15 seconds | 10 seconds | 8 seconds | 5 seconds |
| Denoising steps | 8 (DMD-2 distilled) | Not disclosed | Not disclosed | Standard + Fast modes | Standard |
| Native audio | Yes, joint generation | Yes, native sync | Yes, native sync | Yes, native sync | Optional, separate |
| Lip-sync languages | 7 (reported) | 8+ | 1 | English-focused | Not natively supported |
| API availability | Late April 2026 (pending) | Live | Live | Live | Live |
| Open weights commitment | Promised, not shipped | Closed | Closed | Closed | Partial open |
Read Next
For a broader ranking that now sits Happy Horse 1.0 above the rest of the field, see the AI Video Generators Ranked 2026 guide. For a three-way breakdown of the former top tier, the Seedance vs. Kling vs. Veo comparison is the best starting point.
Pricing: What Is Verified vs. Projected
Pricing status verified April 30, 2026. Happy Horse 1.0 pricing is PROJECTED. Official pricing from Alibaba/fal.ai pending. Verified peer pricing sourced from official APIs and fal.ai.
Alibaba has not published pricing for Happy Horse 1.0 as of April 20, 2026. Every specific dollar figure currently on the open web traces back to SEO parasite domains, not to Alibaba or fal.ai. The realistic projection, based on the model’s 8-step inference efficiency and peer benchmarks, is roughly $0.09 to $0.10 per generated second, which would undercut Seedance 2.0 and match Wan 2.2.

Cost-per-Second Comparison
Where pricing is verified against first-party docs and partner listings as of April 2026:
| AI video model | Verified cost per second | Cost for 10-second 1080p clip | Primary segment |
|---|---|---|---|
| Wan 2.2 (via partner APIs) | ~$0.04 per second | ~$0.40 | Prototyping, open dev |
| Kling 3.0 Pro | ~$0.10 per second | ~$1.00 | High-volume social |
| Seedance 2.0 Pro | ~$0.14 per second | ~$1.40 | Commercial ads, director control |
| Veo 3.1 Standard | ~$0.40 per second | ~$4.00 | Premium enterprise |
| Happy Horse 1.0 (projected) | ~$0.09 to $0.10 per second | ~$0.90 to $1.00 | TBD at launch |
For the Seedance 2.0 price point, the $0.14 per second figure is the TechNode report from March 2026 covering ByteDance’s enterprise API. Seedance also raised platform credit costs for a 15-second clip from 45 credits to 120 credits earlier in the year, which the community flagged as a roughly 2.7x jump.
Happy Horse 1.0’s projected price range comes from two signals: the DMD-2 pipeline cuts raw compute by close to half versus 50-step peers, and Alibaba’s existing Wan 2.2 listing on partner cloud providers sits around $0.04 to $0.10 per second. A $0.09 to $0.10 price point would give Alibaba a clean undercut on Seedance 2.0 while reflecting the higher quality tier.
Once fal.ai posts an official endpoint, that projection will be replaced with a verified figure. Do not publish a fixed Happy Horse 1.0 price before then.
Community Pulse: What Creators Actually Say
Early community reaction on r/aivideo, r/singularity, and r/StableDiffusion is a mix of real enthusiasm and real skepticism. Testers praise subject identity, tracking shot stability, and product rendering. They push back on the short clip duration, the empty “open source” GitHub and Hugging Face repos, and the lack of a public API. The short version: benchmark-ready, production-blocked.
What People Like
Users testing the hosted demo consistently call out three strengths. First, tracking shots hold subject identity and background parallax better than Seedance 2.0 or Kling 3.0 in side-by-side prompts. Second, e-commerce creators report the Image-to-Video mode gives the most stable product rendering they have seen from any True Model. Third, the native audio generation actually saves workflow steps: creators who previously stitched in ElevenLabs voiceovers or manually timed Foley are skipping that step entirely for short clips.
What People Criticize
Three recurring complaints:
- Open source in name only. Alibaba’s public messaging points to an Apache 2.0 release. As of April 20, 2026, the GitHub and Hugging Face repositories linked from third-party sites are either 404, empty, or unofficial community mirrors. No first-party weights exist yet.
- Duration ceiling. The 5 to 10 second sweet spot is shorter than Seedance 2.0’s 15 second cap. Creators making narrative shots or longer product demos are keeping Seedance in rotation for that reason.
- Physics chaos edge cases. Power users on r/aivideo report Seedance 2.0 still handles high-intensity physical chaos (rapid limb interaction, dense crowd motion, unstable object stacks) with fewer warping artifacts than Happy Horse 1.0. Happy Horse’s strength is controlled cinematography, not crowd simulation.
Benchmark Skepticism
A smaller but loud group on r/StableDiffusion has flagged that anonymous leaderboard debuts historically favor the debuting model through sampling bias and cherry-picked prompt sets. The counterargument: Artificial Analysis had already logged roughly 15,000 blind pairwise votes on Happy Horse 1.0 within its first week, which is a large enough sample that sustained Elo leadership stops being explainable by variance alone.
Prompting Techniques for Happy Horse 1.0
Happy Horse 1.0 rewards dense, narrative-style prompts with explicit camera language, lighting direction, and timeline structure. Community testing on the hosted demo shows that prompts with focal length, shot direction, and duration tokens outperform bare keyword lists. The model reportedly hits 84% directional accuracy on camera moves, compared to an industry average around 61%.
High-Signal Prompt Tokens
Tokens that produce a measurable quality jump based on community testing:
- Camera moves: dolly-in, dolly-out, tracking shot, orbit, crane up, push-in, whip pan.
- Focal length: 35mm, 50mm, 85mm, wide angle. Specifying a lens changes depth of field and subject framing predictably.
- Lighting direction: backlit, side-lit, front-lit, rim light, golden hour.
- Duration prefix: opening the prompt with
8s duration:or10s duration:paces the action better than leaving it implicit. - Timeline structure: splitting the action into
first / then / finallyreduces identity drift across the clip.
Prompt Structure Example
A high-performing structure from community tests looks like this:
10s duration: A weathered fisherman on a stone dock at sunrise,
slow dolly-in from wide to medium, 50mm shallow depth of field,
backlit golden hour, quiet determination.
First he ties a rope, then watches the horizon, finally smiles.For a broader primer on prompting any 2026 AI video model, see How to Write AI Video Prompts That Actually Work.
Hidden Parameters
No true hidden parameters are documented, because the weights and configuration file are not public. The closest workflow in circulation is two-clip chaining: generate a 5-second clip, grab the final frame, feed it back as the reference image for a matched-seed Image-to-Video call, and stitch the pair. This is a user pattern, not an official feature.
How to Try Happy Horse 1.0 Right Now
As of April 20, 2026, there is no first-party Happy Horse website and no public API. Alibaba’s confirmed distribution partners are fal.ai and WaveSpeedAI, with the public endpoint scheduled for late April 2026. The long list of “happy-horse.*” domains currently on the open web are SEO parasites, not Alibaba properties. Do not pay any of them for access.
Confirmed Channels
- Alibaba’s official X account for the Happy Horse project, posting demo clips and release updates.
- fal.ai Happy Horse 1.0 page, listed as the launch partner for the public API.
- WaveSpeedAI, hosting the second official endpoint at launch.
- Artificial Analysis Video Arena, where the public blind-test arena still lets you compare Happy Horse outputs against peer models without an account.
Channels to Avoid
Any domain claiming to be the official Happy Horse website (happyhorse.app, happy-horse.art, happyhorse-ai.com, happyhorseai.xyz, happyhorseprompts.com, and similar variants) is not an Alibaba property. Several of them collect payment for “early access” that does not exist. Until fal.ai or WaveSpeedAI publishes the endpoint, there is no paid access channel.
Why This Matters for AI Video Creators
Happy Horse 1.0 changes the default assumption that top-tier AI video quality has to be slow, cascaded, and closed. A 15B single-stream model hitting #1 in blind tests while running at 38 seconds per 1080p clip signals that 2026’s next wave of tools will be unified-architecture-first and distillation-first. For AI Video Bootcamp members, that means prompting patterns, pricing assumptions, and workflow tooling built around Seedance 2.0 and Veo 3.1 all need a refresh.
What to Do This Week
- Watch for the fal.ai endpoint launch in late April 2026 and benchmark it against your current Seedance 2.0 or Veo 3.1 workflow on a matched prompt set.
- If you are paying for a high-volume Seedance plan, delay any annual commitment until Happy Horse pricing is confirmed. A 30% per-second savings at volume is realistic if the $0.09 to $0.10 projection holds.
- Start building your prompt library around the narrative-plus-cinematography structure above rather than keyword lists. That style ports cleanly across True Models and specifically rewards Happy Horse 1.0.
For the broader picture of where AI video is going in 2026, see The State of AI Video Creation in 2026 and 60+ Generative AI Statistics 2026.
FAQ
What is Happy Horse 1.0?
Happy Horse 1.0 is Alibaba’s 15-billion-parameter AI video generation model, built by the Taotian Future Life Lab under Zhang Di. It generates Text-to-Video and Image-to-Video output at native 1080p with synchronized audio, and currently holds the #1 global ranking on the Artificial Analysis Video Arena for both categories without audio.
Who made Happy Horse 1.0?
Happy Horse 1.0 was developed inside Alibaba’s ATH AI Innovation Unit, specifically by the Taotian Future Life Laboratory. The technical lead is Zhang Di, formerly a Vice President at Kuaishou and the primary technical lead on the Kling AI video model before joining Alibaba in late 2025.
Is Happy Horse 1.0 available to use right now?
Not via a public API yet. As of April 20, 2026, Alibaba has confirmed late-April 2026 launches on fal.ai and WaveSpeedAI. A hosted demo surfaces through partner blogs, but any domain claiming to be the “official” Happy Horse site is an SEO parasite, not an Alibaba property.
How much does Happy Horse 1.0 cost?
Alibaba has not published official pricing. Based on the 8-step DMD-2 inference efficiency and Alibaba’s existing Wan 2.2 listing near $0.04 to $0.10 per second, the credible projection sits around $0.09 to $0.10 per generated second, or roughly $0.90 to $1.00 for a 10-second 1080p clip. Wait for the fal.ai endpoint to confirm.
Is Happy Horse 1.0 better than Seedance 2.0 or Veo 3.1?
In blind pairwise votes on the Artificial Analysis Video Arena, yes. Happy Horse 1.0 leads Seedance 2.0 by roughly 100 Elo points on Text-to-Video without audio and holds #1 on Image-to-Video without audio. Seedance 2.0 still edges it on high-intensity physics chaos and longer 15-second clips. Veo 3.1 remains competitive on audio-enabled categories.
Sources
- Alibaba revealed as creator of AI video generation model HappyHorse-1.0 - CNBC, April 10, 2026
- Alibaba Claims Viral Happy Horse AI Model in Latest Breakthrough - Bloomberg, April 10, 2026
- Artificial Analysis Video Arena - Happy Horse model family
- Happy Horse 1.0 on fal.ai - official API provider page
- ByteDance’s Seedance 2.0 costs about $0.14 per second - TechNode, March 2026
- Improved Distribution Matching Distillation for Fast Image Synthesis (Yin et al., 2024, arXiv:2405.14867)
- Alibaba claims viral happy horse AI model in latest breakthrough — The Star, April 13, 2026.