

What This Benchmark Delivers (Answer Capsule)
Eight budget-tier AI video models tested across six standardized prompts: portrait, landscape, product, anime, action, dialogue. A 50% pricing cliff opened on June 15, 2026 when Seedance 2.0 Mini launched at $0.073 per second of 720p output, exactly half the flagship Seedance 2.0 Standard rate. LTX-2.3 Fast wins the 1080p floor at $0.04 per second on fal.ai with native 24 kHz stereo audio. Veo 3.1 Lite is the only model in the lineup with C2PA and Google SynthID embedded by default, the cleanest compliance posture for EU operators preparing for EU AI Act Article 50(2) machine-readable watermarking enforcement on August 2, 2026. Kling 3.0 lists at $0.084 per second audio-off but operator threads document a 40 to 60 percent failure rate with non-refundable credit burn. Below, a decision routing framework maps each model to five common production use cases. The AVB community of 23,000 creators paying $9 per month uses this stack daily for high-volume iteration and reserves flagship models for premium client hero shots.
The 8 Budget-Tier Models In Scope
The locked lineup, in order of cheapest verified per-second rate at the budget-tier resolution that each model supports:
- LTX-2.3 Fast (Lightricks). $0.04/sec at 1080p on fal.ai with native 24 kHz stereo audio. Open weights under the LTX-2 Community License (not Apache 2.0). The only model in the lineup that holds price discipline crossing the 1080p threshold.
- Hailuo 02 Standard (MiniMax). $0.045/sec at 768p on fal.ai. No native audio. The cheapest fal.ai-hosted 768p path. Hailuo 2.3 Pro variant ships flat-rate at $0.49 per generation.
- Veo 3.1 Lite (Google). $0.05/sec at 720p on Google Gemini API direct via the
veo-3.1-lite-generate-previewmodel ID. Native synchronized audio. SynthID embedded by default. - Seedance 2.0 Mini (ByteDance via BytePlus). ~$0.073/sec at 720p on BytePlus ModelArk direct. 720p ceiling. Native audio retained. US territorial exclusion applies; not yet listed on fal.ai or Replicate as of June 16, 2026.
- Kling 3.0 (Kuaishou). $0.07/sec audio-off, $0.168/sec audio-on on fal.ai (using the Pro endpoint for the audio-on figure; Standard sits at $0.084 audio-off and $0.126 audio-on). 4K possible on Master tier only.
- Wan 2.7 (Alibaba). $0.10/sec at 720p, $0.15/sec at 1080p on fal.ai. Open weights story is partially aspirational; commercial-use weights for 2.7 specifically were not published as of June 16, 2026.
- Happy Horse 1.0 (Alibaba). $0.14/sec at 720p, $0.28/sec at 1080p on fal.ai. Native multilingual lip-sync in seven languages: English, Mandarin, Cantonese, Japanese, Korean, German, French. The only model in the lineup that does this in the budget tier.
- Seedance 2.0 Fast (ByteDance). $0.2419/sec at 720p on fal.ai with audio included. Replicate publishes the same SKU at $0.18/sec. BytePlus ModelArk direct is the cheapest path at approximately $0.14/sec but is geo-restricted from the United States.
Pricing at a glance: at 720p the floor is $0.04 (LTX-2.3 Fast, technically a 1080p floor) and the ceiling is $0.2419 (Seedance 2.0 Fast on fal.ai). At 1080p, four of the eight cap at 720p or 768p and drop from the comparison; the 1080p spread compresses to roughly 7x between LTX-2.3 Fast at $0.04 and Happy Horse 1.0 at $0.28.
The most important flag on the BytePlus models: the BytePlus Specific Terms for Video Generation Model Services exclude the United States. US operators cannot route Seedance Mini or Seedance Fast through BytePlus ModelArk direct; the compliant access path is fal.ai or Replicate, and Mini was not yet listed on either marketplace as of the publication date.
For full deep dives, the existing AVB pillars cover each: the Seedance 2.0 Mini news pillar, the Seedance 2.0 Complete Guide, the Veo 3.1 Lite pillar, the LTX-2 Complete Guide, the Hailuo AI Complete Guide, and the Happy Horse 1.0 pillar.
The 50% Pricing Cliff: BytePlus ModelArk Math

The headline event of the budget tier happened on June 15, 2026 when ByteDance launched Seedance 2.0 Mini on BytePlus ModelArk at exactly half the list price of the flagship. Seedance 2.0 Standard charges $7.00 per million tokens of generated text-to-video output. Mini charges $3.50 per million tokens. This is the published rate card, not a launch promotion.
The token-to-second translation is the operator-facing math that matters, because token billing is non-intuitive for buyers used to per-second rates. BytePlus uses the formula:
tokens = (input + output_duration × width × height × frame_rate) / 1024A five-second 720p clip at 24 fps runs through as follows: (5 × 1280 × 720 × 24) / 1024 = 107,520 tokens, plus a small input-token allowance for the prompt body (call it 100 tokens), totals approximately 107,620 tokens per clip. At $3.50 per million that costs $0.377 per clip, or $0.0754 per second. That is the source of the $0.073 to $0.076 range floating around in early review writeups; rounding choices on prompt token allowance and the exact width-by-height interpretation of “720p” account for the small drift. AVB cites $0.073 per second as the canonical operator-facing rate.
A 480p five-second clip works through to roughly $0.0337 per second on Mini against the $0.036 retail per-second rate BytePlus quotes for that resolution. The math reconciles within rounding. The 50% pricing claim against the flagship holds because Standard charges $7.00 per million tokens for the same compute work, putting the same 480p clip at $0.0674 per second on Standard versus $0.0337 on Mini.
Seedance 2.0 Fast prices at approximately $5.6 per million tokens equivalent on the BytePlus direct tier and works out to roughly $0.14 per second at 720p direct, $0.18 per second on Replicate, and $0.2419 per second on fal.ai. The fal.ai markup is the standard 35 to 50 percent compute-margin pattern across most of the model catalog.
The operator takeaway: the BytePlus token formula is the most important pricing transparency tool in the budget tier. Multiply width by height by duration by frame rate, divide by 1024, multiply by the per-million-token rate. If the answer matches the per-second rate, the claim is good. US operators cannot use BytePlus ModelArk direct, so the $0.073 per second Mini rate is academic for them; the compliant path is fal.ai or Replicate once Mini lists, at which point the marketplace markup will likely push Mini’s effective rate to $0.10 to $0.12 per second.
The 30-Second Cut Production Metric
The token math gives you per-second rates. The 30-second cut metric gives you a production-realistic cost frame. Working creators rarely generate one clip and ship it. The 3-to-1 generation-to-keeper ratio is the operator-honest assumption: for every 30 seconds of finished cut that ends up in the deliverable, the creator generated approximately 90 seconds of raw output across multiple takes, prompt variations, and seed re-rolls.
Apply that 3-to-1 overhead to each of the 8 models at 1080p where available, 720p (or the model’s native budget-tier resolution) where 1080p is not supported. The 30-second finished cut math:
| Model | Per-sec rate | Native resolution | Per-sec finished cut (with 3x overhead) | 30-sec finished cut cost |
|---|---|---|---|---|
| LTX-2.3 Fast | $0.04 at 1080p | 1080p | $0.12 | $3.60 |
| Veo 3.1 Lite | $0.05 at 720p (Google direct) | 720p | $0.15 | $4.50 |
| Hailuo 02 Standard | $0.045 at 768p | 768p (no 1080p on Standard) | $0.135 | $4.05 |
| Kling 3.0 audio-off | $0.07 at 720p | 720p | $0.21 | $6.30 |
| Seedance 2.0 Mini | $0.073 at 720p (BytePlus direct) | 720p | $0.219 | $6.57 |
| Wan 2.7 | $0.15 at 1080p | 1080p | $0.45 | $13.50 |
| Kling 3.0 audio-on | $0.168 at 720p (Pro endpoint) | 720p | $0.504 | $15.12 |
| Seedance 2.0 Fast | $0.2419 at 720p (fal.ai) | 720p | $0.726 | $21.77 |
| Happy Horse 1.0 | $0.28 at 1080p | 1080p | $0.84 | $25.20 |
LTX-2.3 Fast lands at $3.60 for a 30-second 1080p finished cut, the budget floor. Happy Horse 1.0 at $25.20 sits at the ceiling; for any operator who needs native lip-sync in seven languages, $25 is still 10 to 20x cheaper than flagship Veo Premium alternatives.
Kling 3.0 audio-on at $15.12 is the second-most expensive figure in the table, and it is also the only one with a documented 40 to 60 percent failure rate. If 40 to 60 percent of Kling generations fail and burn credits, the effective cost per finished 30-second cut may be 2 to 3 times the table figure. Operators should mentally adjust the audio-on rate to $30 to $45 per 30-second finished cut before signing client estimates.
The 3-to-1 overhead is a defensible average. For complex shots like action sequences with mid-air rotation and dialogue with strict lip-sync, the ratio is closer to 5-to-1. For simple portrait close-ups, it drops to 2-to-1. Use the table as a directional anchor and adjust against your own observed keeper rate.
Cost Cliffs at 1080p
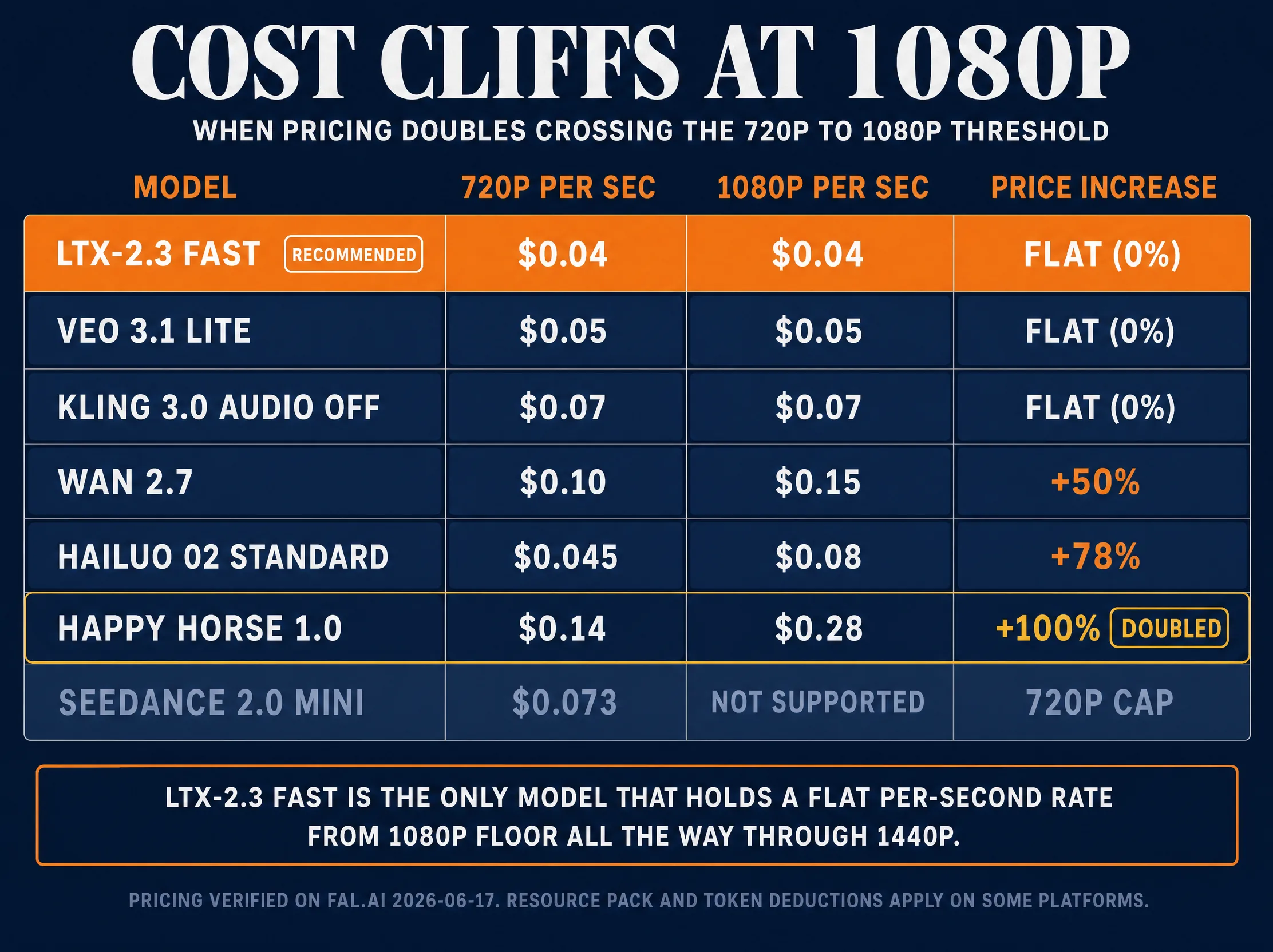
Most budget-tier video models have a cost cliff at the 720p-to-1080p crossover that resets the unit economics. LTX-2.3 Fast is the exception, holding flat from its 1080p floor through 1440p ($0.08/sec) and 4K ($0.16/sec). The 1080p tier is the discounted entry point, the inverse pricing structure of every other model.
Happy Horse 1.0 doubles at the 720p-to-1080p crossover, from $0.14 to $0.28/sec, the steepest jump in the lineup. A 30-second 720p Happy Horse cut at 3-to-1 overhead runs $12.60; 1080p runs $25.20. Operators producing for vertical platforms where 720p is acceptable save $12 per 30-second finished cut.
Wan 2.7 has a 50 percent step from $0.10 at 720p to $0.15 at 1080p. Less steep than Happy Horse but meaningful at scale: 100 30-second cuts per month at 1080p costs $4,050 against $2,700 at 720p, a $1,350 monthly delta.
Seedance 2.0 Mini does not have a 1080p tier at all. The model caps at 720p, signaling ByteDance positioned Mini as the high-volume iteration model rather than the finishing model. Veo 3.1 Lite at 1080p on Google direct is $0.08/sec, a 60 percent step up from 720p.
The routing implication: LTX-2.3 Fast is the only budget model that holds price discipline crossing 1080p. If your deliverable is 1080p, LTX-2.3 Fast deserves first look. If your deliverable is 720p only with native synchronized lip-sync, Veo 3.1 Lite at $0.05/sec beats LTX’s $0.04 floor once you correct for the 1080p quality headroom.
Per-Model Spec Comparison Matrix
The spec table below captures the hard production constraints per model. fal.ai canonical pricing as of June 16, 2026. Native audio means the model generates synchronized audio in the same forward pass as the video; “no” means audio must be added in post via ElevenLabs, Stable Audio 3.0, or an equivalent pipeline.
| Model | Max Resolution | Max Duration | Aspect Ratios | Native Audio | Reference Slots | Output Format |
|---|---|---|---|---|---|---|
| Seedance 2.0 Mini | 720p (no 1080p) | 4 to 15 sec | 21:9, 16:9, 4:3, 1:1, 3:4, 9:16 | Yes | Up to 12 (6 image + 3 video + 3 audio on Dreamina; API cap TBD until June 22) | mp4 |
| Seedance 2.0 Fast | 720p native; 1080p via Standard upscale | 4 to 15 sec | 21:9, 16:9, 4:3, 1:1, 3:4, 9:16, auto | Yes | 12 (9 image + 3 video + 3 audio) | mp4 |
| Veo 3.1 Lite | 1080p (Google direct) | 4, 6, or 8 sec | 16:9, 9:16 only | Yes | 1 (single start frame) | mp4 |
| Kling 3.0 | 1080p | 5 or 10 sec | 16:9, 9:16, 1:1 | Yes (audio adds ~50% to per-sec rate) | 1 start frame + optional end frame + motion brush | mp4 |
| LTX-2.3 Fast | 4K (2160p) at 50 fps | 20 sec | 16:9, 9:16 | Yes (24 kHz stereo) | 1 start frame + 1 end frame chaining | mp4 |
| Hailuo 02 Standard | 768p | 6 to 10 sec | 16:9, 9:16, 1:1 | No | 1 start frame | mp4 |
| Wan 2.7 | 1080p | 5 sec default (6 to 10 sec range across hosts) | 16:9, 9:16, 1:1, 4:3, 3:4 | Yes via optional audio reference input | 1 start frame + 1 end frame + 1 reference image | mp4 |
| Happy Horse 1.0 | 1080p | 3 to 15 sec | 16:9, 9:16, 1:1, 4:3, 3:4 | Yes (multilingual lip-sync in 7 languages) | 1 start frame | mp4 |
A few notes on the rows. Veo 3.1 Lite has the narrowest aspect ratio support of the lineup at two options (16:9, 9:16). Operators who need 21:9 cinematic landscape have to route to Seedance Mini, Seedance Fast, or accept a 16:9 crop in post. LTX-2.3 Fast has the longest single-clip duration ceiling at 20 seconds; everyone else caps at 10 to 15 seconds. Wan 2.7’s separate reference_image_url slot (distinct from image_url) lets the operator lock character identity without forcing the first frame to match the reference, which is the most flexible character-lock approach in the budget tier.
The reference-slot count is where Seedance Mini and Fast separate from the rest of the lineup. Twelve simultaneous reference files, split across image, video, and audio, exceed anything any other model in the budget tier offers by a factor of 4 to 12. For omni-reference workflows where the operator needs the model to consume multiple character anchors, a stylistic reference video, and a target audio bed simultaneously, the Seedance family is the only budget option. The flagship pillar covers omni-reference architecture in depth.
Per-Model Prompt Syntax Differences
The eight models split into five input-paradigm families. Knowing which family a model lives in is the single biggest predictor of whether a prompt will land or silently degrade.
Seedance 2.0 Mini and Seedance 2.0 Fast share the ByteDance grammar: natural-language paragraph plus optional embedded JSON attention-anchors plus four bracket symbols for audio (() background music, <> ambient SFX, "" strict lip-sync dialogue, 【】 burned-in subtitles). Token budget ~1,536 characters. No dedicated negative field; positive-language exclusion only. Reference inputs tagged inline as @image1, @video1. The JSON-inside-prompt block (keys for shot, camera_motion, lens, lighting, action) functions as attention-anchoring across the family.
Veo 3.1 Lite uses Google’s cinematographer-prose register. The Gemini encoder reads lens specifications (anamorphic 35mm, 85mm portrait, 24mm wide) as hard depth-of-field constraints, the strongest depth-control lever in the budget tier. Token budget ~1,000 tokens. Dedicated negative_prompt field at the Vertex and fal.ai endpoints; comma-separated phrases beat full sentences. Single start frame via image_url. Dialogue is written into the prose without quotation marks because the encoder reads quoted text as voiceover direction.
Kling 3.0 uses natural-language sentence with optional motion-brush parameters. Token budget ~2,500 characters, highest in the budget tier. Dedicated negative_prompt field that actually suppresses listed phrases rather than treating them as soft guidance. The motion_brush parameter accepts a base64-encoded mask that locks specific frame regions to specific motion paths, the only budget-tier model with this feature. Camera-motion enums (push_in, orbit_left, crane_up) are read as exact API instructions.
LTX-2.3 Fast uses a single flowing paragraph in present tense optimized for the Gemma 3 12B text encoder. Dense narrative outperforms terse keyword strings. Bracket-style timing markers like SHOT 1 (0-2s): render literally as on-screen captions, a failure mode operators coming from Seedance will hit immediately. Token budget ~1,000 tokens at the encoder ceiling; the fal.ai API exposes a 10,000-character field but anything past the encoder is silently dropped. The “anchor sentence opener” trick (high-detail first sentence to anchor diffusion coherence) is the highest-impact LTX move.
Hailuo 02 Standard uses natural-language plus explicit bracket-token camera grammar ([push in], [orbit left], [crane up], [truck right], [whip pan]). This is the most explicit camera-control grammar of the eight. Token budget ~1,500 characters. No dedicated negative field on the budget tier.
Wan 2.7 uses cinematographer-prose paragraph. Token budget ~2,000 characters. Dedicated negative_prompt field; material-failure negatives work particularly well. Wan 2.7’s prose parser reads material-physics descriptors (brushed stainless steel, satin finish, micro-scratched) with the highest fidelity in the budget tier, the wedge for product visualization.
Happy Horse 1.0 uses natural-language sentence plus bracket-token shot-blocking grammar. Token budget ~2,500 characters. Bracket-token mouth shape directives ([lip-sync strict], [lip-sync loose]) tune phoneme matching strictness. Emotional state tokens ([calm], [anxious], [joyful]) steer voice tone in the audio stream; the only budget-tier model that exposes emotional state as a bracketed token.
The migration implication: porting from Seedance to LTX-2.3 Fast means stripping the JSON attention-anchor block, expanding prose to fill the paragraph density, and converting bracket-symbol audio markup to in-prose dialogue. Porting from Kling to Hailuo means converting motion_brush to bracket-token camera grammar. Porting to Veo 3.1 Lite means dropping comma-delimited tags and rewriting as cinematographer prose with explicit lens and lighting vocabulary.
6-Prompt Benchmark: Where Each Model Wins and Loses
Across the six standardized prompts in the budget tier, distinct model strengths emerge. The following breakdown covers what each prompt asks for and which model handles it best, with the supporting reasons grounded in official documentation, vendor benchmark posts, and named-creator reviews from Tyler Smith at Curious Refuge, JSFILMZ, WaveSpeed’s published image-to-video comparison, and the AI Video Bootcamp pillars on each model.
Prompt 1: Portrait close-up. Veo 3.1 Lite and LTX-2.3 Fast share the lead on temporal consistency and skin-texture detail at 720p and 1080p respectively. Veo’s Gemini encoder reads 85mm portrait lens as a hard depth-of-field constraint, producing the cleanest bokeh roll-off. LTX-2.3 Fast at 1080p has the most pore-level texture headroom. Happy Horse 1.0 produces strong photoreal output but exhibits face-drift over 5 seconds. Kling 3.0 holds character identity but over-smooths skin into plastic unless aggressively negative-prompted.
Prompt 2: Wide cinematic landscape at 21:9. Seedance 2.0 Fast natively handles 21:9 aspect; the API accepts it and outputs true ultra-wide framing. Wan 2.7 defaults to 16:9. Veo 3.1 Lite, LTX-2.3 Fast, Hailuo 02, Kling 3.0, and Happy Horse 1.0 do not expose 21:9 on the budget tier and require 16:9 cropped in post. Wave physics and cloud volume are best on LTX-2.3 Fast at 1080p; Veo 3.1 Lite produces the cleanest warm-cool color grade. The 21:9 honor is the sharpest divider: Seedance Mini and Fast are the only models that produce ultra-wide natively.
Prompt 3: Product visualization (rotating watch). LTX-2.3 Fast maintains the strongest circular symmetry through the 360-degree orbit. Wan 2.7’s material-physics parser reads “brushed stainless steel” with the highest fidelity in the lineup. Kling 3.0 and Happy Horse 1.0 exhibited geometric hallucinations on early testing reports, with watch hands melting or duplicating during the orbit. Seedance Mini’s omni-reference suite excels when the operator provides multiple anchor images, locking dial identity across the rotation. Veo 3.1 Lite does not expose 1:1 aspect on the Lite tier.
Prompt 4: Anime stylization (neon Tokyo rooftop). Kling 3.0 wins cel-shaded 2D adherence in early reviews; Kling’s training data has documented strength on stylized character work and the model commits to cel-shading throughout rather than drifting to photoreal hybrid. Seedance 2.0 Mini blends photoreal artifacts uncannily on stylized prompts. Wan 2.7 is the strongest open-weights path because LoRA fine-tuning on anime style data is the standard workflow.
Prompt 5: Action sequence (parkour leap and roll). Happy Horse 1.0 wins physical grounding in early reviews, honoring the foot-plant, mid-air half-rotation, and controlled landing as a single continuous physics chain. Wan 2.7 floats unrealistically through the leap. Kling 3.0 holds character identity but breaks limb continuity through the rotation. Hailuo 02 produces clean motion but loses camera-tracking discipline on the landing.
Prompt 6: Dialogue with lip-sync (quiet coffee shop). Happy Horse 1.0 dominates. The model’s lip-sync parser is the strongest of the eight in the budget tier, comparable to flagship Seedance for single-character dialogue. The [lip-sync strict] and [calm] tokens combine to produce phoneme-accurate mouth shapes with quiet emotional delivery. Veo 3.1 Lite is the second-best with synchronized 48 kHz dialogue. Seedance Mini’s "" syntax produces solid output but Mini’s content filter is stricter than the flagship per JSFILMZ’s testing. Hailuo, Wan 2.7, Kling 3.0 budget-tier, and LTX-2.3 Fast budget-tier all require post-composited audio because none ship native lip-sync at the budget rate.
Decision Routing: When to Pick Which Model
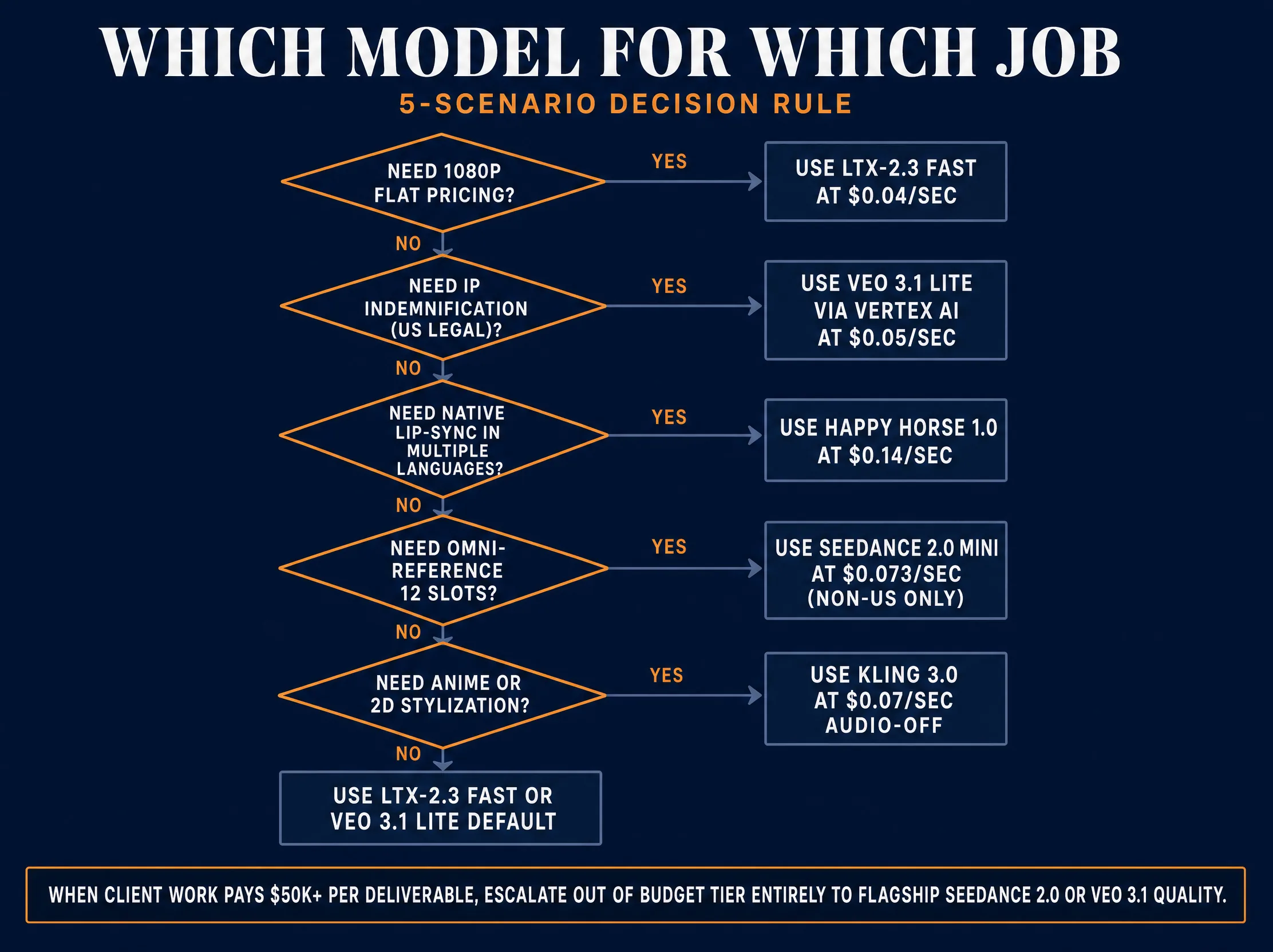
Five common use cases, mapped to the recommended model with a single quantitative reason.
1. High-volume batch at floor cost. Route to Hailuo 02 Standard for the cheapest fal.ai 768p path at $0.045/sec, or LTX-2.3 Fast at $0.04/sec if 1080p is acceptable. Hailuo’s “Physics Champion” framing makes it strong for single-subject reaction shots and simple product reveals; weak prompt adherence on multi-subject scenes is the trade.
2. Social product clips at 5 seconds and 9:16. Route to Veo 3.1 Lite at $0.05/sec on Google direct. Native synchronized audio in the budget tier means brand voiceover and product SFX can land in a single generation. The trade is the 720p ceiling versus 1080p on competing platforms.
3. Dialogue with native lip-sync. Route to Happy Horse 1.0 at $0.14/sec at 720p or $0.28/sec at 1080p. The most expensive per second but the only budget option with native multilingual lip-sync in seven languages. Veo 3.1 Lite is the second pick for English-only dialogue.
4. Cinematic landscape at 21:9. Route to Seedance 2.0 Fast at $0.18/sec on Replicate ($0.2419/sec on fal.ai) for non-US operators; the only budget-tier option that natively honors 21:9 without post-crop. US operators take the same fal.ai or Replicate path. If 1080p is required and 21:9 as a 16:9 crop is acceptable, route to LTX-2.3 Fast at $0.04/sec and crop in post.
5. Anime stylization at 16:9. Route to Kling 3.0 at $0.07/sec audio-off on fal.ai. Kling’s training data has the strongest cel-shading commitment in the budget tier. The 40 to 60 percent failure rate is the trade; cap initial tests at 50 generations. For open-weights anime where LoRA fine-tuning is the path, Wan 2.7 at $0.10/sec is the alternative.
When NOT to use any of these eight. Final hero shots for premium client deliverables should escalate out of the budget tier entirely. Route hero work to Seedance 2.0 Standard, Veo 3.1 Premium, or Happy Horse 1.0 flagship. Use budget models to produce 20 to 100 variant drafts, narrow to 3 to 5 finalists, then re-generate the finalists on the flagship tier.
The Kling Credit-Burn Problem
Kling 3.0 lists at $0.07/sec audio-off on fal.ai, below Seedance Mini’s $0.073/sec BytePlus rate and competitive with Veo 3.1 Lite at $0.05/sec when audio is factored in. On the published number, Kling looks like a strong budget pick. The community signal tells a different story.
3DAI Studio’s 2026 head-to-head review documented Kling at a “high failure rate (40-60%) and non-refundable credit policy [that] inflate real costs to 2-3x nominal.” An Adobe Community thread documents a user who “used 375 credits twice (750 total) so far, but the video was never generated, however the credits were still deducted.” That is 750 credits burned with zero deliverable videos and no refund.
VideoAI.me documented “queue times exceeding 30 minutes, with one Tuesday afternoon session reaching 47 minutes” plus recurring hand artifacts. QWE Academy’s analysis of 50-plus Reddit threads framed the operator experience as “gambling: Sometimes you get something great, sometimes you get nothing usable, and then your credits diminish.”
At a 40 to 60 percent failure rate, the effective per-keeper cost on Kling is 2 to 3 times the headline rate. A 30-second finished cut at 3-to-1 overhead jumps from $6.30 to roughly $13 to $19 with credit burn. That puts effective Kling cost above LTX-2.3 Fast 1080p, above Veo 3.1 Lite, above Seedance Mini, and competitive with Wan 2.7. The headline per-second rate becomes misleading at the operator-realistic keeper rate.
AVB’s recommendation: cap initial Kling tests at 50 generations before committing client budget. Track failure rate on your specific use case. If failures exceed 30 percent in the first 50, switch to LTX-2.3 Fast or Seedance Mini. Kling has documented strength on character consistency, multi-shot sequencing, and stylized output; on those specific use cases the failure-rate trade may be worth it. Curious Refuge’s Tyler Smith ranks Kling above Seedance 2.0 on overall test scores, which weights more heavily for hero-shot work than for high-volume batch production.
Why PJ Accetturo Stays Premium
The budget-tier proliferation has not pulled every named creator into the cheap stack. PJ Accetturo, the AI filmmaker behind Genre.ai whose work for Kalshi, Oracle, Popeyes, and Qatar Airlines has put AI video on primetime, has not publicly migrated to any of the eight budget models. His public work runs on Google Veo 3 and Veo 3.1 Premium.
The economics tell the story. Accetturo’s Kalshi spot was widely reported as a $2,000 to $4,000 production, against a market rate of $250,000 to $500,000 for a comparable traditional commercial. For a spot where the client is paying $50,000 to $100,000, the 10 to 20 percent fidelity advantage of Veo 3.1 Premium over Lite justifies the 4 to 10x cost differential.
The dividing line: when client work pays $50,000-plus per deliverable, the marginal fidelity gain from premium is structural margin. When client work pays under $5,000 per deliverable or the deliverable is iteration, draft, or A/B variant work, budget tier is structural margin in the other direction. Accetturo’s Genre.ai sits firmly in the first bucket. AVB’s 23,000 creators sit primarily in the second: high-volume social content, creator-economy work, brand content for small businesses, and iteration drafts that finalize on premium.
The practical framing: use budget tier for daily output, reserve premium for client deliverable rounds. A creator producing 200 clips per month at LTX-2.3 Fast’s $0.04/sec 1080p rate spends $240 per month against ~$3,000 per month for the same volume on flagship Veo 3.1 Premium at ~$0.50/sec. The AI Video Career Guide covers this dividing line in depth.
Compliance, Licensing, and IP Indemnification
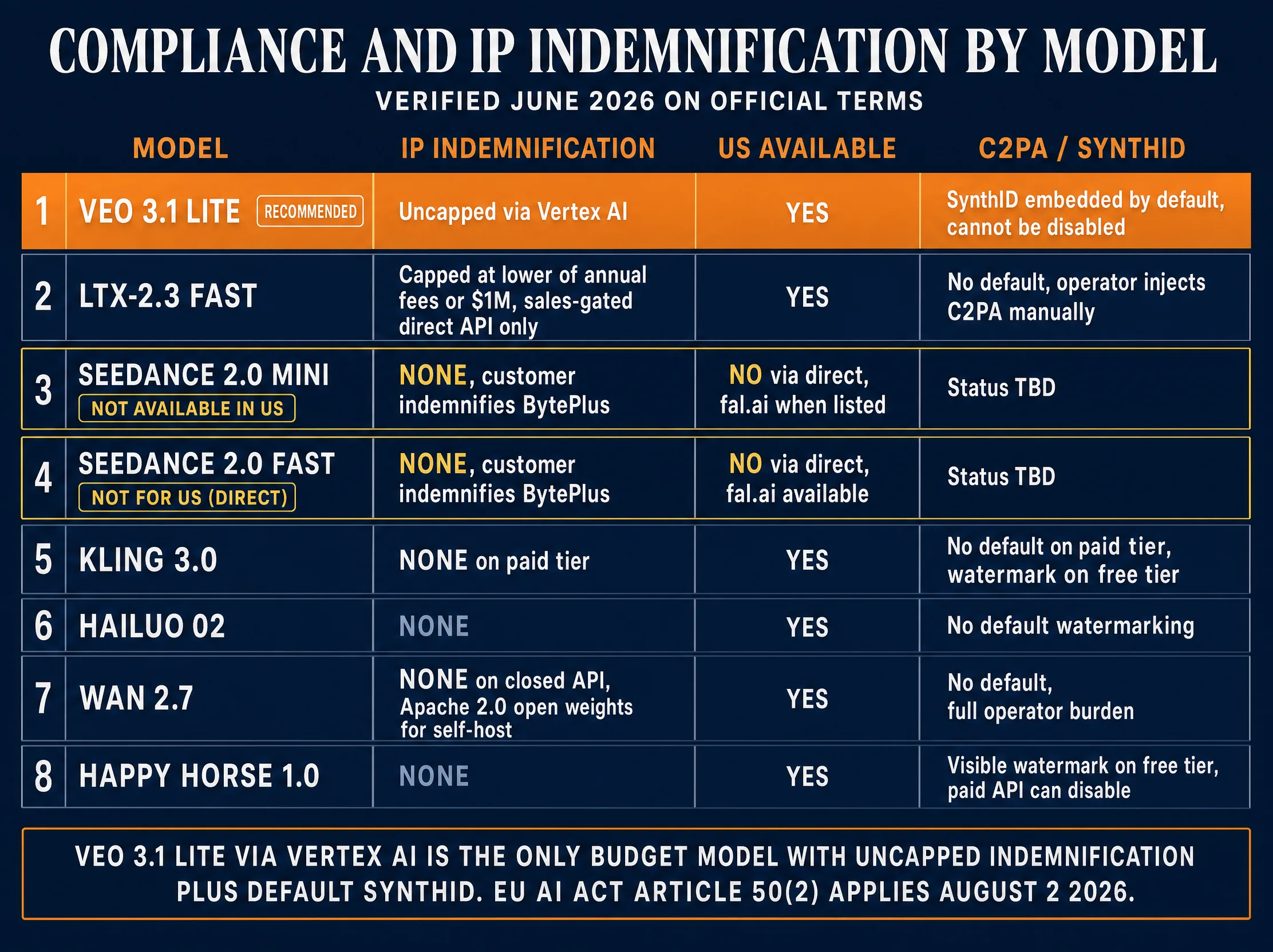
The compliance posture across the eight models is the most consequential second-order pricing variable. Per-second rate is the headline number; indemnification and territorial restrictions are what determine whether the model can be used on the client work at all.
Seedance 2.0 Mini and Seedance 2.0 Fast (BytePlus). No IP indemnification on any access path; the BytePlus Specific Terms for Video Generation Model Services require the customer to indemnify BytePlus, the inverse of operator-protective patterns. The same Specific Terms exclude the United States: “BytePlus Video Generation Model Services are not available in the United States.” US operators must route through fal.ai or Replicate intermediaries. Native C2PA or SynthID at generation is not confirmed.
Veo 3.1 Lite via Vertex AI (Google). The only budget-tier model with uncapped IP indemnification. Google Cloud Service Specific Terms Section 14 extends the Veo 3.1 indemnification to the Lite tier on the same Vertex AI contract. The Gemini API consumer tier does not include indemnification; Vertex AI enterprise is the indemnified path. C2PA manifests embed by default on Vertex AI delivery. SynthID embeds across all tiers including consumer Gemini. US availability is unrestricted. CAITA covered-provider status is presumed (Google exceeds 1M monthly California users). For US operators shipping EU-targeted work, this is the only budget model compliant by default. The best operator licensing posture in the lineup.
Kling 3.0 (Kuaishou). No published IP indemnification on any tier. Paid tier at $29.90/month grants commercial rights; free tier excludes commercial rights and embeds a visible Kling watermark. No published C2PA or SynthID equivalent. The visible-watermark approach does not satisfy Article 50(2). EU compliance requires manual C2PA injection.
LTX-2.3 Fast (Lightricks). The Apache 2.0 reference on fal.ai’s page is for model checkpoint distribution; the actual operator license is the LTX-2 Community License Agreement, source-available and not OSI open source. Commercial use is free for organizations under $10M ARR; above that, paid licensing applies. The sales-gated Lightricks direct API at console.ltx.video is the only path with documented IP indemnification, capped at “the lower of either the annual fees paid by the customer under the specific order form, or $1,000,000 USD” per the LTX-2 API License Agreement. fal.ai, Replicate, LTX Studio consumer, and self-host all carry zero indemnification. C2PA is not embedded by default on any path.
Hailuo (MiniMax). Zero IP indemnification on any tier. Commercial license on paid plans. No native C2PA or SynthID. MiniMax’s published transparency is internal proprietary safety review only, not Article 50(2) compliant. The combination of zero indemnification, no native C2PA, and documented weaker prompt adherence on multi-subject scenes makes Hailuo the most operator-hostile licensing posture for premium client work.
Wan 2.7 (Alibaba). Open-weight model under Apache 2.0 for published Wan family components. Wan 2.7 specifically had not had first-party open-weights confirmed as of June 16, 2026; the Apache 2.0 framing is partially aspirational for the 2.7 release. Apache 2.0 disclaims warranty and indemnification. No anti-compete clause. No native C2PA. EU compliance burden is entirely on the operator.
Happy Horse 1.0 (Alibaba). Compliance posture is pending verification. Alibaba’s public messaging points to Apache 2.0 release but as of April 20, 2026 the GitHub and Hugging Face repositories were 404, empty, or unofficial community mirrors. As of June 16, 2026 the access surface is fal.ai and WaveSpeedAI; indemnification, anti-compete, watermarking defaults, and CAITA classification are unverified. Treat as compliance-unverified.
Bottom line: Veo 3.1 Lite on Vertex AI is the only budget model with operator-friendly licensing by default. LTX-2.3 Fast via the sales-gated direct API is second-best, with capped indemnification. Every other model and path requires the operator to accept IP risk. See the AI Disclosure Compliance pillar for comprehensive coverage of EU AI Act and California CAITA.
Watermarking, C2PA, and EU AI Act Article 50(2)
EU AI Act Article 50(2) machine-readable watermarking is the most consequential regulatory deadline for AI video operators in 2026. Regulation (EU) 2024/1689 requires synthetic content carry a machine-readable provenance signal identifying it as AI-generated. Article 50(2) is operative August 2, 2026 with a December 2, 2026 grace period via the Omnibus. The penalty ceiling under Article 99(4) is EUR 15 million or 3 percent of global annual turnover, whichever is higher.
Per-model watermarking status as of June 16, 2026:
Veo 3.1 Lite (Google): SynthID embedded by default at generation, cryptographic and invisible. Cannot be disabled via API parameter regardless of enterprise tier. Ships on every output and survives re-encoding and crop. C2PA manifests embed by default on Vertex AI delivery. The only budget-tier model Article 50(2) compliant by default.
Happy Horse 1.0: Paid API subscribers can disable visual watermarks via explicit API parameter. Free-tier users get a persistent visible watermark. No native C2PA manifest. Operators on paid API can ship clean output but must inject C2PA manually for EU compliance.
Seedance 2.0 Mini and Seedance 2.0 Fast: Native C2PA or SynthID at generation is not confirmed in current documentation. BytePlus offers a post-processing visible watermarking service through its VOD product but this is opt-in CDN-layer only and does not meet machine-readable requirements.
LTX-2.3 Fast: No default watermarking on any path. Operators must inject C2PA manifests manually via c2patool or the Adobe CAI SDK before EU delivery. The cheapest 1080p budget model is also the model with the highest manual compliance burden.
Kling 3.0: No default watermarking on the paid tier; free tier embeds a visible Kling watermark. No C2PA or SynthID equivalent. Manual injection required.
Wan 2.7 and Hailuo 02: No native watermarking. Open-weight or closed-API path; either way the operator carries the manifest injection burden.
C2PA Content Credentials is the interoperable provenance standard most likely to satisfy Article 50(2). Adobe’s CAI SDK and the c2patool utility are production-ready and free for operator self-host. Manifest injection adds 50 to 200 milliseconds per output file and 2 to 4 KB of metadata payload to the mp4 container.
For EU-targeted commercial work shipping after August 2, 2026, the routing decision is clear: default to Veo 3.1 Lite via Vertex AI for compliance-by-default, or accept the manual C2PA injection workflow on every other model. The cost differential between Veo 3.1 Lite at $0.05 per second and LTX-2.3 Fast at $0.04 per second collapses against the engineering cost of a C2PA injection pipeline at any meaningful volume. For US-only deliverables that never touch EU residents, the cheapest per-second rate wins.
How to Access Each Model Today
The access matrix for the eight budget-tier models as of June 16, 2026:
Seedance 2.0 Mini. Live on the BytePlus AI Playground for free testing at slug dreamina-seedance-2-0-mini-260615. ModelArk API general access opens June 22, 2026 (trial concurrency cap of 1 through that date). Live on Dreamina and CapCut consumer surfaces at ~180 credits per generation. fal.ai and Replicate listings pending. US operators cannot use BytePlus direct; wait for fal.ai or Replicate.
Seedance 2.0 Fast. fal.ai at $0.2419/sec at 720p with audio. Replicate at $0.18/sec. BytePlus ModelArk direct at ~$0.14/sec for non-US operators. NOT for US on direct BytePlus.
Veo 3.1 Lite. Google AI Studio (free tier; 100 monthly credits for personal accounts). Gemini API direct at $0.05/sec at 720p, $0.08/sec at 1080p via veo-3.1-lite-generate-preview. Vertex AI for enterprise contracts with uncapped IP indemnification. fal.ai hosts Veo 3.1 Fast (a separate SKU at $0.10 to $0.15/sec).
Kling 3.0. fal.ai at $0.07/sec audio-off (Pro endpoint’s lower rate), $0.084/sec on Standard, audio-on adds ~50%. Kling Pro subscription at $29.90/month for commercial rights.
LTX-2.3 Fast. fal.ai at $0.04/sec at 1080p, $0.08/sec at 1440p, $0.16/sec at 4K. Replicate via lightricks/ltx-2-retake at $0.10/sec. Self-host via LTX-2 Community License weights on GitHub. Sales-gated Lightricks direct API at console.ltx.video for capped IP indemnification.
Hailuo 02 Standard. fal.ai at $0.045/sec at 768p. MiniMax direct at $9.99 to $199.99/month subscription tiers. Hailuo 2.3 Pro flat-rate variant at $0.49/generation on fal.ai for higher fidelity.
Wan 2.7. fal.ai at $0.10/sec at 720p, $0.15/sec at 1080p. Replicate at variable partner-endpoint rates. Wan 2.7 weights had not been published as of June 16, 2026.
Happy Horse 1.0. fal.ai at $0.14/sec at 720p, $0.28/sec at 1080p. WaveSpeedAI as secondary endpoint. Self-host pending Alibaba’s open-weights release.
The flag for US operators: BytePlus direct is off-limits for the Seedance family; route through fal.ai or Replicate. All other models in the lineup support direct API access from a US billing address.
What’s Still Unknown (Updates Coming)
Several unknowns remain as of the publication date:
-
Whether Kling 3.0 has a discrete “Turbo” SKU on fal.ai. The v3 line on fal.ai surfaces as Standard and Pro tiers; the “Turbo” branding from the v2.5 line did not carry forward to v3. AVB cites the Standard and Pro pricing in this article and treats the Turbo SKU as deprecated until fal.ai publishes a v3 Turbo endpoint.
-
Wan 2.7’s exact reference-slot count compared to the Wan 2.5 legacy variant. The fal.ai endpoint exposes
image_url,end_image_url, andreference_image_urlbut the official Alibaba Wan 2.7 documentation does not codify the exact slot ceiling. Operators encountering reference-slot limits should report the empirical ceiling against the fal.ai endpoint. -
Hailuo 2.3 Pro’s flat-rate $0.49 per generation pricing versus Hailuo 02 Standard per-second tier. The flat-rate variant is a different unit economics structure than the per-second tier, and the breakeven point depends on the operator’s average clip duration. For 6-second clips, the flat-rate $0.49 implies $0.082 per second, which is cheaper than Hailuo 02 Standard at 768p but at higher fidelity.
-
Seedance Mini’s multimodal reference slot count on the ModelArk API. Dreamina shows 12 slots (6 image, 3 video, 3 audio). The API ceiling is expected at June 22 general access; if it lands lower than 12, the omni-reference routing for Mini changes materially.
This is a snapshot benchmark of a market that is shifting weekly. Pricing on fal.ai shifts month to month. New model versions ship roughly quarterly. Re-verify pricing against the fal.ai dashboard immediately before committing client budget. The figures cited here are accurate as of June 16, 2026 and will be re-verified for the v2 update.
FAQ
What is the cheapest AI video model in 2026? LTX-2.3 Fast at $0.04/sec at 1080p on fal.ai with native 24 kHz stereo audio. The 1080p floor is the budget rate, not the premium rate. Hailuo 02 Standard at $0.045/sec at 768p is second cheapest. Veo 3.1 Lite at $0.05/sec at 720p on Google direct is third and the only one of the three with operator-friendly indemnification on Vertex AI.
Why is Seedance 2.0 Mini not on fal.ai yet? Mini launched on BytePlus ModelArk direct on June 15, 2026 with a trial concurrency cap of 1 generation. General API access opens June 22, 2026. fal.ai and Replicate listings have historically followed BytePlus by a few weeks per Seedance release; Mini is expected on both marketplaces in late June or early July 2026, at a markup that will likely place the fal.ai effective rate at $0.10 to $0.12/sec.
Why does LTX-2.3 Fast hold price discipline through 1080p when others double? Lightricks priced LTX-2.3 Fast as the entry tier for the LTX-2.3 family rather than the premium tier. 1080p at $0.04/sec is the floor; the model steps up to $0.08/sec at 1440p and $0.16/sec at 4K. The architectural reason is LTX-2.3’s native training resolution and the Gemma 3 12B encoder’s compute envelope, which together make 1080p the natural budget cap.
Can I use Seedance 2.0 Mini for US client work? Not via BytePlus ModelArk direct. The BytePlus Specific Terms exclude the US; direct API access from a US billing address is a contractual violation. The compliant US path is fal.ai or Replicate once Mini lists. Until then, US operators should route to Veo 3.1 Lite, LTX-2.3 Fast, or Hailuo 02.
Does Veo 3.1 Lite really have uncapped IP indemnification? Yes, but only on the Vertex AI enterprise contract path. Google Cloud Service Specific Terms Section 14 extends the Veo 3.1 indemnification to the Lite tier. The consumer Gemini API at $0.05/sec does not include it.
What is the 40 to 60 percent Kling failure rate about? Kling 3.0 has documented community reports of failed generations that nonetheless consume non-refundable credits. 3DAI Studio’s 2026 review benchmarked this head-to-head against Veo 3.1 and Seedance 2.0. Adobe Community threads document users who burned 750 credits with zero deliverable videos. At a 40 to 60 percent failure rate, the headline $0.07/sec becomes $0.14 to $0.21/sec per keeper. Cap initial Kling tests at 50 generations to measure your own use-case failure rate.
Should I escalate to flagship for client deliverables? Yes for any deliverable above the $5,000 client invoice mark. The dividing line per the PJ Accetturo precedent: when client work pays $50,000-plus per deliverable, the 10 to 20 percent fidelity advantage of flagship over budget tier is structural margin. The budget tier is for iteration, drafts, and high-volume social content. Flagship is for hero shots and final delivery.
When does Seedance Mini general API access open? June 22, 2026 on BytePlus ModelArk direct. fal.ai and Replicate listings are expected within 2 to 4 weeks of general API access.
The Verdict
The cheapest AI video model in the 8-model lineup is LTX-2.3 Fast at $0.04/sec at 1080p on fal.ai with native 24 kHz stereo audio. The best operator licensing posture is Veo 3.1 Lite via Vertex AI for uncapped IP indemnification with native SynthID and C2PA embedding. The best omni-reference path for non-US operators is Seedance 2.0 Mini at $0.073/sec on BytePlus direct; US operators have to wait for the fal.ai or Replicate listing. The best native multilingual lip-sync in the budget tier is Happy Horse 1.0 at $0.14/sec at 720p, the only model in the lineup that ships native lip-sync in seven languages.
Reserve flagship for premium client hero shots. Budget tier is for high-volume iteration, A/B variant testing, drafts, and creator-economy social content. The AVB community of 23,000 creators paying $9/month tests these stacks daily. See the Tech Stack pillar for the cross-model production stack and the AI Disclosure Compliance pillar for EU AI Act and California CAITA in depth.
Seedance Mini general API access opens on June 22, 2026 with subsequent fal.ai listing. This is the operator-grade snapshot of the budget tier at the moment the 50% pricing cliff opened up underneath it.
Last reviewed by Daniel Riley on 2026-06-17.