

LTX-2 is Lightricks Lab’s open-weights AI video generation model, with LTX-2.3 (released March 5, 2026) as the current 22-billion-parameter version. It is the only True Model in the 2026 video stack that ships open weights and generates synchronized 4K video plus audio in a single diffusion pass, the only one offering native 4K at 50 fps, and the only one with a documented (if capped) IP indemnification path on its primary cloud API. The architecture is an asymmetric dual-stream Diffusion Transformer combining a 14-billion-parameter video stream with a 5-billion-parameter audio stream and bidirectional cross-modal attention, per the arXiv 2601.03233 paper. This guide covers product identity, the three fal.ai product tiers, ComfyUI self-host workflow with VRAM math, head-to-head benchmarks against the True Model lineup, and the EU AI Act and California AB 853 compliance picture for client work shipping after August 2, 2026.
What Is LTX-2?
Answer capsule. LTX-2 is Lightricks’ open-weights AI video foundation model, currently shipping as LTX-2.3 (released March 5, 2026) at 22 billion parameters. The architecture is an asymmetric dual-stream Diffusion Transformer: a 14B-parameter video stream with 3D Rotary Positional Embedding plus a 5B-parameter audio stream with 1D RoPE, joined by bidirectional cross-modal attention. It is the only True Model in 2026 that generates synchronized video and audio in a single forward pass with open downloadable weights.
Lightricks is a Jerusalem-headquartered creative-software company founded in 2013 by Zeev Farbman and four co-founders. The consumer product portfolio (Facetune, Videoleap, Photoleap) has accumulated more than 730 million downloads with 15 million monthly active users per the Lightricks corporate page. The company reached a 1.8 billion USD valuation following a 130 million USD Series D in September 2021, with total cumulative funding of 335 million USD across four rounds. The LTX research division is led by Yoav HaCohen as Generative AI Research Team Lead, who is the first author on the LTX-2 arXiv paper.
The LTX-2 lineage:
- LTX-Video (LTX-1) released late 2024 / early 2025 as the original 2B-class video-only model with no audio capability.
- LTX-2 (19B) released January 6, 2026 as the first dual-stream architecture combining a 14B video stream and a 5B audio stream with native synchronized output.
- LTX-2.3 (22B) released March 5, 2026 with a rebuilt Variational Autoencoder for sharper textures, an upgraded HiFi-GAN audio vocoder, gated attention text conditioning, native 9:16 portrait support, 24/48 FPS options, last-frame interpolation, and LoRA fine-tuning.
Native audio generation is the architectural achievement. Rather than the conventional “generate video, dub audio in post” pipeline, LTX-2.3 denoises video and audio latents inside the same diffusion pass with cross-attention. The audio path processes input as 16 kHz mel-spectrograms encoded by the Audio VAE into 128-dimensional latent tokens at roughly one token per 1/25 of a second, then a HiFi-GAN V1 vocoder with doubled generator capacity reconstructs the output as 24 kHz stereo waveforms with lip sync, foley, and ambient sound. The text encoder is Google Gemma 3 12B Instruction-Tuned, adapted via the UL2 objective and producing specialized “thinking tokens” that improve semantic stability and phonetic accuracy.
LTX-2 Specifications and Architecture
Answer capsule. LTX-2.3 generates synchronized video and audio up to 20 seconds at resolutions from 480p through native 4K (2160p) at frame rates up to 50 fps. The aspect ratio supports both 16:9 landscape and 9:16 portrait (added in 2.3). The Video VAE compresses 33 frames of 512x512 pixel data into a tensor with a compression ratio exceeding 150x. Frame counts must follow the formula (n times 8) plus 1, yielding valid lengths of 9, 17, 25, 57, 121, 241, and so on. Width and height must be strictly divisible by 32. Any deviation fails the generation request.
Specifications verified against the Hugging Face Lightricks/LTX-2.3 model card and the arXiv paper:
| Specification | LTX-2.3 |
|---|---|
| Total parameters | 22 billion (14B video + 5B audio + connector layers) |
| Architecture | Asymmetric dual-stream Diffusion Transformer |
| Transformer layers | 48 |
| Maximum resolution | 2160p (4K) native |
| Maximum frame rate | 50 fps |
| Maximum duration | 20 seconds |
| Native audio | 24 kHz stereo with lip sync, foley, ambient |
| Audio sample rate (input) | 16 kHz mel-spectrograms |
| Audio sample rate (output) | 24 kHz HiFi-GAN V1 vocoder |
| Aspect ratios | 16:9 landscape, 9:16 portrait |
| Text encoder | Google Gemma 3 12B IT (UL2 adapted) |
| Text encoder context (effective) | ~1,000 tokens (~750 English words) |
| Image conditioning | Start frame, end frame, multi-keyframe |
| LoRA fine-tuning | Supported on Quality tier |
The Gemma 3 12B encoder is a load-bearing technical detail with operational consequences. Although the fal.ai API exposes a 10,000-character prompt field, the encoder context window is throttled to roughly 1,000 tokens, and anything past that is silently dropped before the diffusion sampler sees it. Operators writing long narrative prompts past 750 English words are wasting characters.
NVIDIA has featured LTX-2 at both GDC 2026 (RTX AI Garage) and CES 2026, with NVFP4 and NVFP8 datatype support delivering up to 2.5x performance gains and 60 percent lower VRAM usage on RTX 50-series cards. The Lightricks team trained LTX-2 on Google Cloud TPUs via JAX, then partnered with NVIDIA for inference optimization, per the Lightricks Google Cloud case study.
Pricing and Access Paths in 2026
Answer capsule. LTX-2.3 ships in three fal.ai product tiers with two billing models. Fast at 0.04 USD per second 1080p for either text-to-video or image-to-video. Pro at 0.06 USD per second 1080p for image-to-video or 0.08 USD per second 1080p for text-to-video (a 33 percent T2V premium most articles miss). Quality on the separate ltx-2.3-quality SKU bills per megapixel at 0.0024075 USD, or 0.0027075 USD with LoRA fine-tuning. All three tiers include native audio. There is no 720p tier; the floor is 1080p across all endpoints.

Cloud pricing matrix (fal.ai, verified 2026-06-05)
| Endpoint | 1080p | 1440p | 2160p (4K) |
|---|---|---|---|
| Fast text-to-video | 0.04 USD/s | 0.08 USD/s | 0.16 USD/s |
| Fast image-to-video | 0.04 USD/s | 0.08 USD/s | 0.16 USD/s |
| Pro image-to-video | 0.06 USD/s | 0.12 USD/s | 0.24 USD/s |
| Pro text-to-video | 0.08 USD/s | 0.16 USD/s | 0.32 USD/s |
| Quality image-to-video | 0.0024075 USD/MP | 0.0024075 USD/MP | 0.0024075 USD/MP |
| Quality audio-to-video | 0.0024075 USD/MP | 0.0024075 USD/MP | 0.0024075 USD/MP |
| Quality LoRA image-to-video | 0.0027075 USD/MP | 0.0027075 USD/MP | 0.0027075 USD/MP |
A 10-second 1080p generation costs 0.40 USD on Fast, 0.60 USD on Pro image-to-video, 0.80 USD on Pro text-to-video, or 1.20 USD on Quality image-to-video. A 60-second social media campaign requiring six 10-second clips runs 2.40 USD on Fast versus 3.60 USD on Pro image-to-video. That same campaign on Veo 3.1 Quality at 0.40 USD per second would cost 24.00 USD, which is the operator-relevant arbitrage decision documented later in the head-to-head section.
Alternative cloud hosts
- Replicate runs the lightricks/ltx-2-retake endpoint at 0.10 USD per video-second for editing existing clips.
- Lightricks LTX Studio consumer subscription at ltx.io/studio/pricing bundles credits: Free with 800 one-time credits, Lite at 12 USD per month (personal only), Standard at 28 USD per month with commercial license, Pro at 100 USD per month with 110,000 credits.
- Lightricks direct API is sales-gated at console.ltx.video. This is the only access path with documented IP indemnification.
- Krea AI added LTX-2.3 hosting on April 30, 2026 as a bundled seat subscription.
- WaveSpeed, Apatero, MindStudio all expose LTX-2.3 inference for niche workflows.
Self-host
The weights download free from Hugging Face under the LTX-2 Community License. Hardware costs amortize against either an RTX 5090 (32 GB) at approximately 3,200 USD or an RTX 4090 (24 GB) at approximately 2,000 USD on the used market. Break-even versus fal.ai Fast at 0.04 USD per second lands at approximately 25 minutes of finished output per month on the RTX 4090 or 37 minutes per month on the RTX 5090. Critically, the RTX 4090 has a documented duty-cycle ceiling around 8 minutes per month for audio-synced 1080p work because the Gemma 3 text encoder cannot offload cleanly without thrashing the PCIe bus.
How to Use LTX-2: Cloud Tutorial (fal.ai)
Answer capsule. Sign up at fal.ai, generate an API key, and call the text-to-video or image-to-video endpoint with five required parameters: prompt, optional image URL, duration, resolution, and audio toggle. A 10-second 1080p Fast generation costs 0.40 USD and returns a downloadable MP4 in 30 to 90 seconds. Width and height must be divisible by 32. Frame counts must follow the formula (n times 8) plus 1.
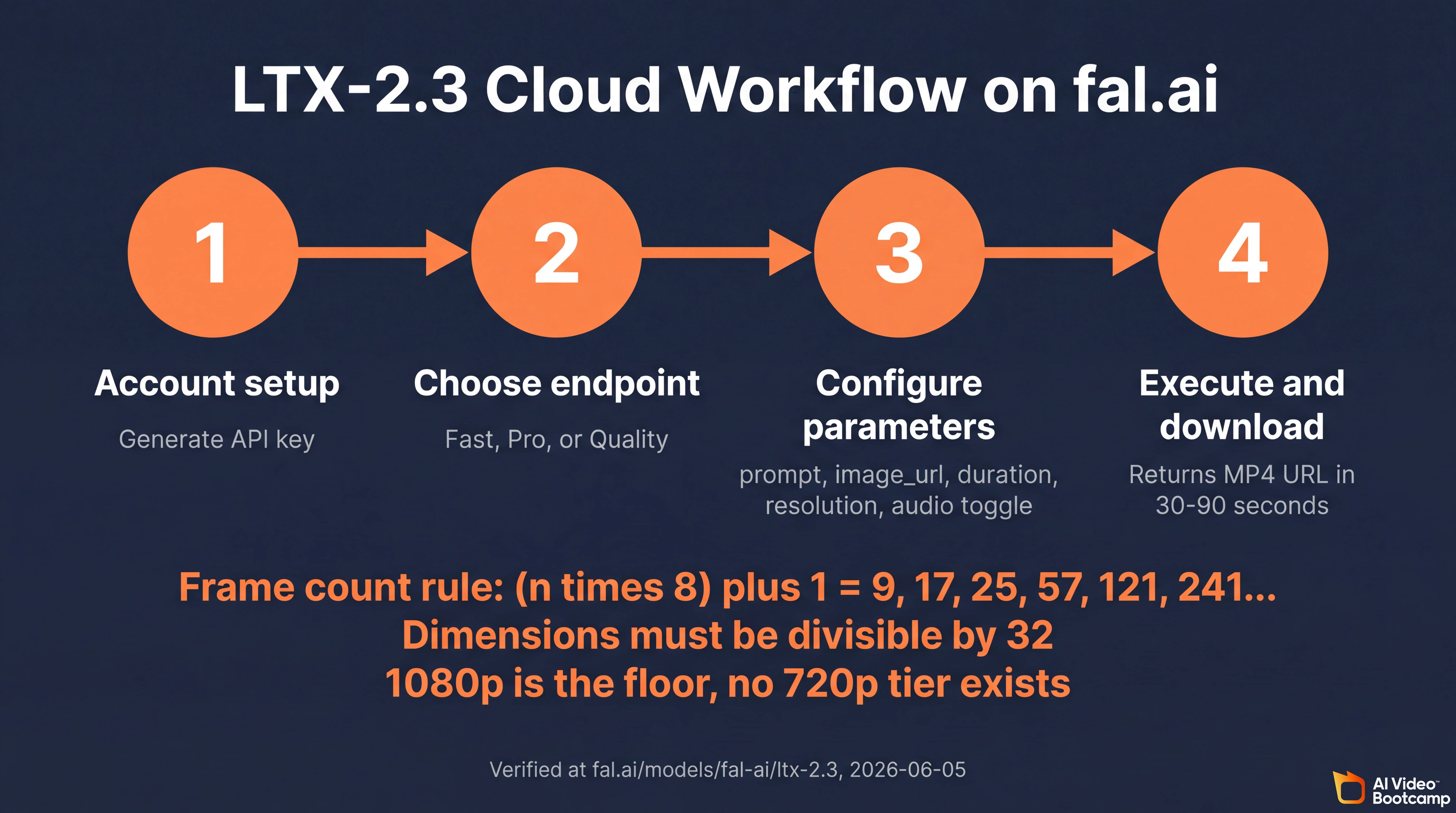
Step 1: Account setup
Navigate to fal.ai, complete account registration, and attach a billing method. New accounts receive a modest free credit pool sufficient for initial testing. Generate an API key from the developer dashboard and store it securely in environment variables, never in code.
Step 2: Choose the right endpoint
Three product tiers with distinct strategic uses:
- Fast for rapid prototyping, B-roll iteration, and cost-sensitive bulk generation
- Pro for client-deliverable quality with the I2V vs T2V cost tradeoff
- Quality for LoRA fine-tuning, audio-to-video workflows, and per-megapixel billing on long-duration shorts
Step 3: Required parameters
{
"prompt": "A middle-aged man speaks in a slow-paced voice, 'I remember that day.' He pauses and looks to the side, then continues, 'It changed everything.'",
"image_url": "https://your-host.com/first-frame.png",
"duration": 10,
"resolution": "1080p",
"aspect_ratio": "16:9",
"generate_audio": true
}Parameter notes:
promptaccepts up to 10,000 characters at the API level but the Gemma 3 encoder context throttles to roughly 1,000 tokens (~750 English words). Past that, content is silently dropped.image_urlis optional for text-to-video and required for image-to-video. Pinterest, Instagram, and Reddit URLs frequently fail because their hosts 403 the fal fetcher; upload via thefal.storage.upload()SDK call instead.durationmust produce a frame count matching the (n times 8) plus 1 formula. At 24 fps, valid durations include 1 second (24 frames rounds to 25), 2.5 seconds (60 rounds to 57), 5 seconds (120 rounds to 121), and 10 seconds (240 rounds to 241).resolutionaccepts “1080p”, “1440p”, “2160p”. There is no “720p” tier on any LTX-2.3 fal.ai endpoint.aspect_ratioaccepts “16:9” or “9:16”. Portrait was added in LTX-2.3.generate_audioboolean. Setting false does not currently reduce per-second cost.
Step 4: Common errors
| Error | Cause | Fix |
|---|---|---|
| HTTP 422 resolution | Specified a tier not exposed (e.g., 720p) | Use 1080p, 1440p, or 2160p |
| HTTP 422 frame count | Duration does not match (n*8)+1 formula | Round to nearest valid frame count |
| HTTP 422 dimension | Width or height not divisible by 32 | Use standard resolutions |
| HTTP 403 image fetch | Upstream image host blocks fal fetcher | Upload via fal.storage.upload() |
How to Use LTX-2: Self-Host Tutorial (ComfyUI v0.16)
Answer capsule. Install ComfyUI v0.16, add the ComfyUI-LTXVideo custom node package from Lightricks, download the LTX-2.3 weights matching your VRAM tier (NVFP4 for RTX 5090, FP8 for RTX 4090, Q4_K GGUF for 16 GB cards), download the Gemma 3 12B text encoder, download the separate audio VAE (102 MB, not auto-fetched by installers), and launch with python -m main --reserve-vram 5 to prevent first-step crashes. The audio VAE omission is the single most common cause of “video has no sound” first-install failures.
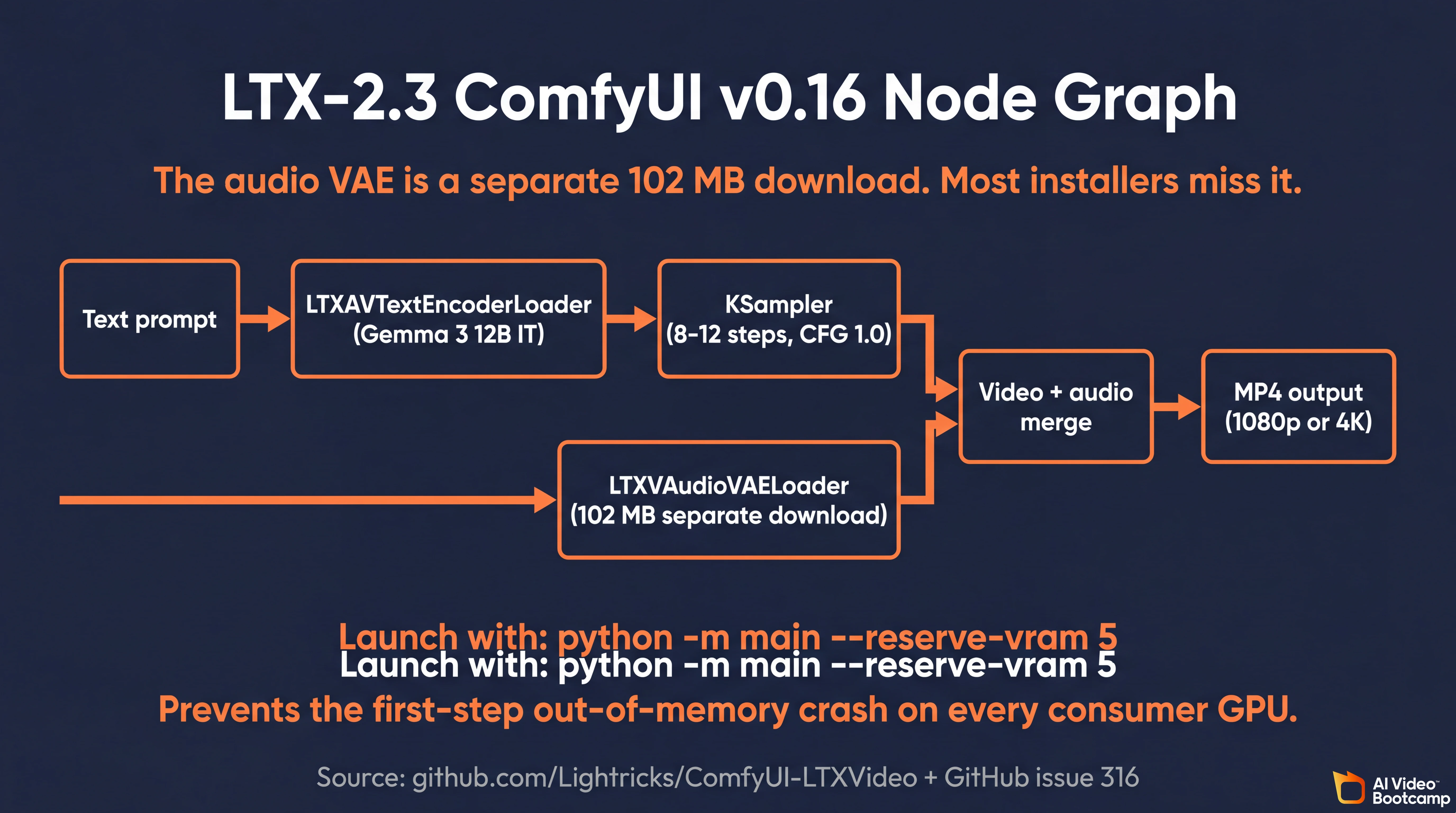
Step 1: Install ComfyUI v0.16 and the LTX-2 node package
Update ComfyUI to v0.16 or later. Open ComfyUI Manager, search for “LTXVideo”, install the official Lightricks/ComfyUI-LTXVideo package, and restart. Windows users running ComfyUI Desktop must install Git from git-scm.com first; the Desktop build does not ship with Git and Manager-installed custom nodes will fail without it.
Step 2: Download the weights for your hardware
Match your quantization to your VRAM:
| Hardware tier | Recommended quantization | Hugging Face download |
|---|---|---|
| RTX 6000 Ada (48 GB) or A100 80 GB | bf16 full | Lightricks/LTX-2.3 |
| RTX 5090 (32 GB) | NVFP4 | Lightricks/LTX-2.3-nvfp4 |
| RTX 4090 (24 GB) | FP8 | Lightricks/LTX-2.3-fp8 |
| RTX 5080 (16 GB) or RTX 4080 SUPER | NVFP4 + projection-only Gemma | NVFP4 base + extracted text encoder |
| RTX 4070 Ti (16 GB) | Q4_K GGUF | unsloth/LTX-2.3-GGUF |
Place main checkpoints in models/checkpoints/. Place the Gemma 3 12B text encoder in models/text_encoders/. Place the spatial and temporal latent upscalers (ltx-2.3-spatial-upscaler-x2-1.1 and ltx-2.3-temporal-upscaler-x2-1.0) in models/latent_upscale_models/.
Step 3: Download the audio VAE separately (load-bearing)
The audio VAE is a 102 MB file at huggingface.co/Lightricks/LTX-2/tree/main/audio that auto-installers and the popup template do not fetch automatically. Without it, video generates correctly but the MP4 plays silent with no error message. Per GitHub issue 316, this is the most common first-install failure. Place the file in models/vae/.
Step 4: Build the canonical node graph
Standard audio-visual LTX-2.3 ComfyUI workflow:
- Text prompt feeds
LTXAVTextEncoderLoader(Gemma 3 instructions) - Visual generation runs through standard
KSamplerwith 8-12 steps and CFG 1.0 for distilled models - Audio generation routes through
LTXVAudioVAELoaderwhich decodes 16 kHz mel-spectrogram latents into 24 kHz waveforms - Outputs merge into a video-combined node multiplexing the .wav track into the .mp4 container
For dual-GPU setups (RTX 3090 plus RTX 4060 Ti is a common community pattern), swap standard loader nodes for the low_vram_loaders.py modules in the LTXVideo repository and use CheckPointLoaderSimpleDisTorch2MultiGPU to isolate the Gemma 3 text encoder on the secondary GPU.
Step 5: Launch with the safety buffer
python -m main --reserve-vram 5The --reserve-vram 5 flag forces ComfyUI to maintain a 5 GB safety buffer, preventing the catastrophic out-of-memory crash that occurs during the massive memory spike on the first diffusion step. Without this flag, even 24 GB cards routinely crash on the initial generation per r/comfyui dual-GPU workflow threads.
LTX-2 VRAM and GPU Requirements
Answer capsule. The minimum honest spec for stable audio-synced LTX-2.3 generation at 1080p is 16 GB of VRAM on a Blackwell-architecture card running NVFP4 with a projection-only Gemma 3 extract. The widely-cited 12 GB minimum claim is wrong because it counts only video weights and silently omits the Gemma 3 12B text encoder, which adds 8.8 GB in FP4 or 28 GB at full precision. Full 20-second 4K generation requires 24 GB on an RTX 4090 or 32 GB on an RTX 5090 for headroom.

VRAM by quantization tier
| Quantization | File size | Peak VRAM (inference) | Peak VRAM with audio | Minimum GPU |
|---|---|---|---|---|
| bf16 full | ~44 GB | ~50 GB+ | ~58 GB+ | A100 80 GB or 2x RTX 6000 Ada |
| FP8 cast | ~22 GB | ~26 GB | ~34 GB | RTX 5090 32 GB or A100 |
| NVFP4 | ~11 GB | ~14 GB | ~22 GB | RTX 5090 (full audio) or RTX 5080 (video only) |
| Q4_K GGUF | ~12-14 GB | ~15 GB | ~24 GB | RTX 4090 or RTX 6000 Ada |
The Gemma 3 12B text encoder is the silent VRAM trap. Community benchmarks claiming “LTX-2 runs on a 12 GB GPU” omit the encoder entirely. With encoder loaded, the actual VRAM floor for any audio-synced output is 16 GB. NVFP4 quantization is only available on Blackwell-architecture cards (RTX 50-series), per NVIDIA RTX AI Garage CES 2026 coverage.
Generation time benchmarks (10-second 1080p with audio)
| GPU | Quantization | Estimated wall-clock |
|---|---|---|
| RTX 5090 | NVFP4 | ~7-9 minutes |
| RTX 4090 | FP8 | ~12-15 minutes |
| RTX 4080 SUPER (16 GB) | NVFP4 video only | ~15-18 minutes (no audio) |
| A100 80 GB | bf16 | ~4-6 minutes |
| RTX 6000 Ada | bf16 | ~6-8 minutes |
Per the Zenn LTX-2.3 RTX 5090 benchmark, LTX-2.3 inference is between 5.7x and 14x faster than Wan 2.2 on equivalent hardware across prompt categories.
Self-host vs cloud break-even math
Amortizing an RTX 5090 (3,200 USD MSRP per GPU Poet pricing data) over a 36-month lifespan plus electricity yields an effective cost per finished second of approximately 0.020 USD on the Fast tier. Break-even versus fal.ai Fast at 0.04 USD per second:
- RTX 4090 (2,000 USD used) breaks even at approximately 25 minutes of finished 1080p output per month, but the duty-cycle ceiling on audio-synced work is approximately 8 minutes per month due to Gemma encoder offload thrashing.
- RTX 5090 (3,200 USD new) breaks even at approximately 37 minutes of finished output per month with no duty-cycle constraint.
- Below those thresholds, fal.ai Fast wins on total cost.
- Above approximately 60 minutes per month, RTX 5090 self-host wins decisively.
For high-volume operators (more than 2 hours of finished output per month), the break-even falls inside the first month versus Veo 3.1 Quality (0.40 USD per second) routing.
LTX-2 Prompt Guide
Answer capsule. LTX-2.3 prompts work best as single flowing paragraphs in present tense, written for the Gemma 3 12B text encoder which interprets long descriptive narrative better than terse keyword strings. Camera direction uses explicit cinematographer terminology (slow dolly in, handheld tracking, whip pan). Dialogue must be in quotation marks with physical acting beats between lines. Avoid bracket-style multi-shot timing markers like “SHOT 1 (0-2s):” because they render literally as on-screen text rather than triggering shot changes.
Structural rules
Write the prompt as a single paragraph in present tense. Match prompt length to video duration: a brief two-sentence prompt applied to a 20-second generation forces the model to hallucinate filler action and degrades temporal consistency. Wide establishing shots require extensive environmental description; extreme close-ups require precise facial morphology and skin-texture detail. The effective text encoder context is approximately 1,000 tokens (~750 English words) despite the 10,000-character API field; anything past that is silently dropped.
Camera control vocabulary
Use precise constraints to reduce unwanted wobble and jitter:
slow dolly in,dolly backhandheld tracking shot,static lock-offwhip pan right,slow pan leftlow-angle push-in,crane shot,aerial pullback
In the negative prompting field, exclude unwanted behaviors: no Dutch angle, no rolling shutter wobble, no lens distortion. For deeper cinematic prompt grammar across all True Models, see the Cinematic AI Video Prompts 2026 pillar.
Dialogue and audio sync
Spoken dialogue must be enclosed in quotation marks with physical acting beats inserted between lines. Example from the LTX-2.3 Prompt Guide on the Lightricks blog:
A middle-aged man speaks in a slow-paced voice, “I remember that day.” He pauses and looks to the side, then continues, “It changed everything.”
Avoid abstract emotional labels like “the man is sad” and use physical cues instead: “his brow furrows, his voice cracks”. Physical cues drive both visual facial animation and audio vocoder tone.
For atmospheric audio, describe the soundscape directly in the prompt: soft ambient music, the sound of rain on pavement, distant coffee shop chatter.
Anti-pattern: bracket multi-shot timing
Prompts in the format SHOT 1 (0-2s): get rendered LITERALLY as captions on the video. Operators coming from Seedance experience (where this syntax works for shot blocking) will get burned. Use prose temporal connectors instead: A beat of silence, then she turns..., Three seconds pass before the camera lifts....
Multi-image and omni-reference conditioning
LTX-2.3 does not support multi-reference arrays equivalent to Seedance’s 12-file omni-reference. Character persistence is solved via three alternative paths:
- Start frame plus end frame chaining through the standard
image_urlandend_image_urlparameters - LoRA fine-tuning on the Quality tier for true character lock across shots
LTXV Adain LatentComfyUI node for extracting style characteristics from reference latents
LTX Studio additionally exposes the “Flux Kontext” tool which lets users pull the pose from Image A while adopting the lighting profile of Image B, per the LTX Studio multi-image references blog post.
LTX-2 vs Veo 3.1, Kling 3.0, Seedance 2.0, Wan 2.7, Happy Horse 1.0
Answer capsule. LTX-2.3 wins clearly on open weights, native 4K at 50 fps, longest duration ceiling (20 seconds), cheapest cloud per-second rate with audio, and the only capped IP indemnification path among non-Veo True Models. It loses clearly on dialog-grade audio (Veo 3.1’s 48 kHz dialogue beats LTX’s 24 kHz), multi-subject physics under load (Seedance 2.0 wins), rigid character lock across 6+ shot storyboards (Kling 3.0 wins), and raw blind-test quality (Happy Horse 1.0 leads on the Artificial Analysis Video Arena).
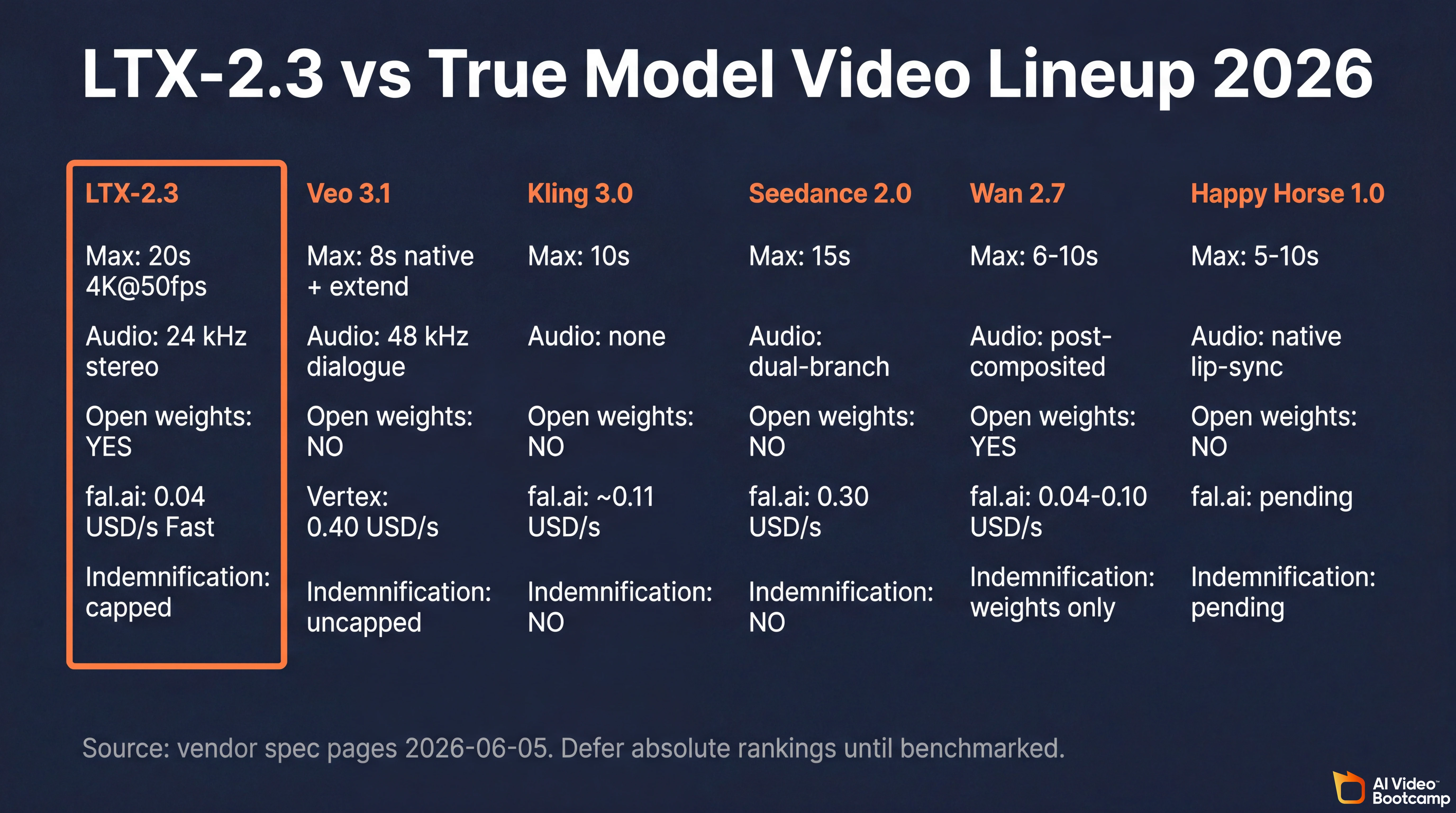
Capability matrix
| Capability | LTX-2.3 | Veo 3.1 | Kling 3.0 | Seedance 2.0 | Wan 2.7 | Happy Horse 1.0 |
|---|---|---|---|---|---|---|
| Max duration | 20s | 8s native, extendable | 10s | 15s | 6-10s | 5-10s |
| Max resolution | Native 4K@50fps | 1080p | 1080p Pro | 720p native, 1080p upscale | 1080p | 1080p |
| Native audio | 24 kHz stereo | 48 kHz dialogue | None | Dual-branch | Post-composited | Native lip-sync |
| Character consistency | Moderate (start/end frame) | Strong | Strong (rigid lock) | Strong (12-file omni-ref) | Moderate | Strong |
| Multi-subject physics | Moderate | Strong | Moderate | Strong | Moderate | Moderate |
| Open weights | Yes | No | No | No | Yes | No |
| IP indemnification (primary cloud) | Capped (lower of fees or 1M USD on direct API only) | Yes (uncapped, Vertex AI) | No | No | Yes (Apache 2.0 weights) | Pending |
| fal.ai cost per second 1080p (Fast/Pro) | 0.04 / 0.06-0.08 USD | 0.40 USD Quality | ~0.11 USD | 0.30 USD Standard | 0.04-0.10 USD | Pending |
When LTX-2 is the right tool
- B-roll arbitrage: 5-second 1080p clip costs 0.20 USD on Fast versus 2.00 USD on Veo 3.1 Quality, a 10x cost differential at viewing-distance-equivalent quality. For Pro I2V the differential is 6.7x; for Pro T2V it’s 5x; for Quality it’s 3.3x.
- Ambient and establishing shots where no on-camera dialog is needed
- Privacy-locked workflows for medical, legal, or defense work that cannot transmit data to external cloud servers (self-host on RTX 6000 Ada is the standard pattern)
- UGC ad pipelines where character + dialog under 20 seconds is the deliverable shape
- High-volume internal content at break-even volumes above 60 minutes finished output per month on RTX 5090 self-host
When LTX-2 is the wrong tool
- Client hero shots requiring uncapped IP indemnification: Veo 3.1 via Google Vertex AI wins under Google Cloud Service Specific Terms Section 14 with no capped liability
- Dialog-grade hero shots: Veo 3.1’s 48 kHz synchronized dialogue beats LTX-2.3’s 24 kHz stereo for broadcast-quality speech
- Extended narrative sequences past 20 seconds: Veo 3.1’s chain-extension capability beats LTX-2.3’s hard 20-second ceiling
- Rigid character lock across 6+ shot storyboards: Kling 3.0’s character consistency mechanism wins
- Multi-subject combat or contact physics: Seedance 2.0 wins for fight choreography and intricate collision
For the broader True Model lineup framing, see the Best AI Video Tools 2026 Tech Stack pillar. For the deepest comparison data on the Seedance side, see Seedance vs Kling vs Veo and the Seedance vs Kling vs Sora 2 API comparison.
Use Cases and Operator Stories
Answer capsule. LTX-2.3 has fundamentally altered agency B-roll economics. The most prominent production use case is high-volume background generation routed away from Veo 3.1 Quality to LTX-2.3 Fast on fal.ai. A standard 60-second social campaign requiring six 10-second clips costs 2.40 USD on Fast or 3.60 USD on Pro image-to-video, versus 24.00 USD on Veo 3.1 Quality. Local privacy-locked workflows on RTX 6000 Ada hardware are the second major use case for enterprise operators handling film studio or defense contractor IP.
Five production use cases
-
B-roll arbitrage: routing background plates, establishing shots, and ambient transition clips from Veo or Kling to LTX-2.3 Fast. The 10x cost cut at indistinguishable viewing-distance quality is the highest-leverage routing decision in the 2026 stack.
-
Ambient and establishing scenes without dialogue: 5-10 second cinematic plates where audio quality is secondary. LTX-2.3 Fast at 1080p with
generate_audio: falsedelivers usable output at 0.04 USD per second. -
UGC ad pipelines (15-30 seconds with character + dialog): LTX-2.3 hits all three requirements simultaneously (audio with passable dialog quality, character lock within a single ad via start/end frame chaining, duration above 10 seconds).
-
Character reels via LoRA fine-tuning: the Quality tier with LoRA support enables true character persistence across multiple shots, at 0.0027075 USD per megapixel of generated video data. A 5-second 1080p character shot runs approximately 0.68 USD.
-
Privacy-locked enterprise workflows: legal, medical, defense, and pre-release film studio clients cannot legally transmit proprietary prompt data or reference imagery to external APIs. Self-host on RTX 6000 Ada or A100 hardware in air-gapped environments is the standard solution.
Outreach: operator case studies wanted
AI Video Bootcamp is sourcing operator case studies for v2 of this guide. Operators running LTX-2.3 in production for client work, especially with documented monthly finished-output volume and a cost-per-second comparison versus prior cloud spend, are invited to reach out via the AI Video Bootcamp homepage contact form. Specific data points being collected: GPU hardware in use, monthly finished output volume, cost-per-second versus prior cloud spend, and one anonymized client deliverable example.
Community Pulse: What Operators Are Saying
Answer capsule. Sentiment across r/StableDiffusion, r/comfyui, and the broader operator community is polarized but predominantly positive. The most-cited praise focuses on the audio capabilities (bypassing secondary TTS tools) and the Gemma 3 text encoder’s prompt adherence. The most-cited frustrations focus on VRAM constraints, the gap between marketing claims (12 GB minimum) and operational reality (16 GB true minimum for audio sync), and the instability of ComfyUI-LTXVideo custom nodes during version updates.
The launch r/StableDiffusion thread for LTX-2 hit approximately 700 upvotes within 48 hours and remains the most-cited community reference. The LTX-2 Hugging Face model page has accumulated over 948,000 monthly downloads, the highest among open-weights video models in 2026.
Lightricks co-founder and CEO Zeev Farbman ran an AMA on r/StableDiffusion announcing the open-source release, stating: “We just open-sourced LTX-2, a production-ready audio-video AI model.” The thread sits at /r/StableDiffusion/comments/1q7dzq2 with deep technical Q&A.
Recurring undocumented prompting tricks from community sources:
- Anchor sentence opener: starting the prompt with a high-detail first sentence anchors the diffusion process and improves overall coherence
- Quantization stacking: combining the Q4_K_M GGUF LTX checkpoint with the FP8-scaled Gemma encoder and a rank175_fp8 distilled LoRA at CFG 4 and 20 steps delivers official-demo-quality output on consumer hardware (RTX 4090)
- Prose temporal connectors: replacing bracket timing markers (
SHOT 1 (0-2s):) with prose (A beat of silence, then...) eliminates the on-screen text rendering bug
Cloud-Managed vs Self-Host: Decision Tree
Answer capsule. Self-host LTX-2.3 if the operator has an RTX 5090 already, generates more than 37 minutes of finished output per month, AND can accept zero IP indemnification. Use fal.ai Fast for any cloud workflow under that volume threshold. Use Lightricks LTX Studio for non-technical creators. Use the sales-gated Lightricks direct API when capped IP indemnification is required.
Operator decision tree
- Do you generate client deliverables requiring uncapped IP indemnification?
- Yes -> Route hero shots through Veo 3.1 on Vertex AI. Use LTX-2.3 only for B-roll and internal work.
- No -> Continue.
- Do you generate more than 60 minutes of finished output per month?
- Yes -> RTX 5090 self-host on NVFP4 wins on cost.
- No -> Continue.
- Do you have an RTX 5090 already?
- Yes -> Self-host on NVFP4 still wins for incremental output cost.
- No -> fal.ai Fast at 0.04 USD per second is the default.
- Are you a non-technical creator?
- Yes -> LTX Studio Standard at 28 USD per month with commercial license.
- No -> fal.ai Fast or Pro tier on the developer dashboard.
Cloud host inventory
| Host | Target user | Pricing model | Indemnification |
|---|---|---|---|
| fal.ai | Developer | Per second (Fast/Pro) or per megapixel (Quality) | None |
| Replicate | Developer | Per video-second on retake endpoint | None |
| LTX Studio | Non-technical creator | Monthly credit subscription | None for consumer plans |
| Lightricks direct API | Enterprise buyer | Sales-gated per-second | Capped at lower of fees or 1M USD |
| Krea AI | Designer | Seat subscription bundle | None |
| WaveSpeed, MindStudio, Apatero | Niche workflows | Varies | None |
The AI Video Bootcamp team is building PromptWise, a managed-hosting platform for AI image, video, and sound generation launching soon. PromptWise will host LTX-2.3 alongside the broader True Models lineup as a curriculum-aligned cloud option for AVB members who want the LTX-2 cost advantages without ComfyUI self-host setup or per-vendor API key management across fal.ai, Replicate, and the Lightricks direct API. This section will be updated with pricing and signup details closer to launch.
Compliance and Commercial Use
Answer capsule. LTX-2.3 weights ship under the LTX-2 Community License Agreement, which is free for commercial use under 10 million USD annual revenue but is NOT Apache 2.0 despite frequent misattribution. IP indemnification is zero on self-host, fal.ai, Replicate, and LTX Studio consumer plans; only the sales-gated Lightricks direct API offers indemnification, capped at the lower of annual fees paid or 1 million USD. C2PA Content Credentials are NOT embedded by default in any access path, creating a load-bearing compliance gap for EU AI Act Article 50 enforcement starting August 2, 2026.

The LTX-2 Community License (read carefully)
The license file at github.com/Lightricks/LTX-2/blob/main/LICENSE does not meet the Open Source Initiative definition of open source. Three defining operational constraints:
- Revenue cap: free commercial use only for entities generating less than 10 million USD in annual revenue across all subsidiaries and affiliates under common corporate control. Entities exceeding this threshold must negotiate a paid Commercial Use Agreement directly with Lightricks.
- Asymmetric indemnification: redistributors must defend Lightricks against claims arising from their use. Lightricks does not indemnify free-weight users in the reverse direction.
- Redistribution restrictions: external API exposure may be treated as redistribution depending on clause interpretation.
The third-party blog framing of LTX-2 as “Apache 2.0” or “fully open source” is incorrect.
Indemnification by access path
| Access path | IP indemnification |
|---|---|
| Self-host from Hugging Face | None. Operator bears all risk. |
| fal.ai endpoints | None disclosed. Pass-through inference. |
| Replicate endpoints | None disclosed. |
| LTX Studio consumer (Free, Lite, Standard, Pro) | None. |
| LTX Studio Enterprise | Custom terms, [UNVERIFIED] without contract. |
| Lightricks direct API (sales-gated) | Yes. Capped at lower of annual fees or 1M USD per the LTX 2 API License Agreement. |
For the broader 2026 indemnification picture across the AI image market, see the AI Image Generators A-Z Encyclopedia. The three-paths-one-trap framing applies in modified form to LTX-2.
EU AI Act Article 50 (effective August 2, 2026)
Article 50 mandates machine-readable disclosure that content is AI-generated. Penalty ceiling: 15 million EUR or 3 percent global turnover. LTX-2.3 does not embed C2PA Content Credentials by default in any access path. Operators serving EU clients after August 2, 2026 must add C2PA manifests manually via c2patool or the Adobe CAI SDK. This is the single biggest operator-facing compliance gotcha. The AI Disclosure Compliance 2026 pillar documents the workflow.
California AB 853 (operative August 2, 2026)
AB 853 enforces both manifest (visible) disclosures and latent (embedded cryptographic) metadata on AI-generated video. Stripping embedded metadata during export constitutes a direct violation. The civil penalty is 5,000 USD per violation per day, enforced by the California Attorney General. Operators must ensure IPTC 2025.1 headers and C2PA signatures survive the final MP4 render through Adobe Premiere, DaVinci Resolve, or CapCut export.
Training data provenance
Lightricks public statements indicate LTX-2 was trained on licensed Getty Images and Shutterstock content. This is the structural IP-risk mitigant since contractual indemnification is bare on most paths. The licensed-data posture is meaningfully stronger than competitors trained on scraped public web data, but it is not a substitute for vendor IP indemnification.
Geographic data residency
fal.ai infrastructure is US-based. Lightricks direct API routes through their own infrastructure documented in the Lightricks Trust Center. EU client work requires a Transfer Impact Assessment under GDPR Article 46 when routing through US-based infrastructure.
FAQ
Is LTX-2 free?
LTX-2 weights are free to download from Hugging Face under the LTX-2 Community License Agreement. Commercial use is free for organizations generating under 10 million USD in annual revenue across all affiliates. Above that threshold, a paid commercial license must be negotiated directly with Lightricks. The license is not Apache 2.0 despite common misattribution.
How much does LTX-2 cost on fal.ai?
fal.ai hosts three LTX-2.3 product tiers. Fast text-to-video and image-to-video both cost 0.04 USD per second at 1080p. Pro image-to-video is 0.06 USD per second at 1080p and Pro text-to-video is 0.08 USD per second at 1080p. The separate Quality SKU bills per megapixel at 0.0024075 USD with LoRA fine-tuning at 0.0027075 USD per megapixel. All tiers include native audio at no extra cost.
What VRAM do I need to run LTX-2 locally?
The widely-cited 12 GB minimum claim is wrong; it counts only video weights and omits the Gemma 3 12B text encoder which adds 8.8 GB in FP4 or 28 GB at full precision. The actual minimum for stable audio-synced 1080p generation is 16 GB on a Blackwell card such as the RTX 5080. Full 20-second 4K generation requires 24 GB minimum.
Does LTX-2 have an API?
Yes. LTX-2.3 is accessible through fal.ai (recommended developer path), Replicate, the sales-gated Lightricks direct API, and partner platforms including WaveSpeed, MindStudio, Apatero, and Krea AI. The Lightricks direct API is the only access path with documented IP indemnification, capped at the lower of annual fees paid or 1 million USD.
Is LTX-2 open source?
Technically no. The LTX-2 Community License Agreement does not meet the Open Source Initiative definition because it includes a commercial-use revenue cap, redistribution restrictions, and asymmetric indemnification terms. The weights are “source-available” for academic and small-commercial use. True OSI-compliant open source in the 2026 video model lineup includes Wan 2.7 and parts of the Hunyuan family.
Last reviewed by Daniel Riley on June 5, 2026. For the broader 2026 AI video model landscape, see the Best AI Video Tools 2026 Tech Stack, the Seedance 2.0 Complete Guide, and the Cinematic AI Video Prompts 2026 pillar. For the open-weights trilogy comparison, see the Happy Horse 1.0 pillar. New to AI Video Bootcamp? Start with What is AI Video Bootcamp.